EPICS Jackie is a pure Java implementation of the Channel Access protocol used by EPICS. It is designed to easily integrate Java applications into EPICS environments without carrying heavy dependencies or even relying on Java Native Interface (JNI) calls to a C library. At the same time, it retains full compatibility with the “standard” implementation of Channel Access that is part of EPICS Base. Please refer to Section 3, “Compatibility” for information about this library’s compatibility.
While this library tries to retain full compatibility on the network layer, its API design differs significantly from that of most other Channel Access libraries. In particular, this library makes use of modern concepts like object-orientation and generics to provide an intuitive yet type-safe programming interface. For a closer look at how this library compares to other implementations, please refer to Section 2, “Comparison with other Channel Access libraries”.
This document is intended as a reference guide on how to use EPICS Jackie. However, it does not intend to describe all the details of the library’s API and its implementation. For a fully detailed description of the API and its standard implementation, please refer to the API reference documentation. This document is intended as a guide to the EPICS Jackie library and not as a guide to the Channel Access protocol itself. If interested in details of the protocol, the reader is encouraged to refer to the EPICS R3.16 Channel Access Reference Manual and the EPICS Channel Access Protocol Specification.
The EPICS Jackie library has been designed with two goals in mind: First, it should be easy and convenient to use it. Second, it should be flexible so that it can be used as a building block for applications with special requirements. Keeping the first goal in mind, this means that the library should offer configurable parameters that modify its behavior but should also provide sensible defaults for these parameters.
In order to attain the goal of providing a library that can be used easily and conveniently, the API has been designed as a first-grade Java API instead of trying to reuse the concepts of the API of the Channel Access library for the C programming language. This means that the Channel Access client, channels, and channel monitors are all represented by objects. These objects are safe for concurrent use by multiple threads, lifting the user from the burden of having to synchronize access to the API by using a mutex.
The API uses generics to enable the user to deal with the various types of Channel Access values in a type-safe way, benefiting from automatic type checks at compile time. This is combined with a class-hierarchy that actually reflects the hierarchy of Channel Access types. This means that (unlike the API of the C library) there are common base-types for all values that provide alarm information and all values that provide display information (the second being derived from the first because display information always includes alarm information).
The asynchronous nature of network communication in general and the Channel Access protocol in particular is reflected in the API by having asynchronous operations return futures that allow the calling code to wait for the operation to finish or to be notified asynchronously when it finishes.
In order to make using this library convenient, dependencies are kept to a minimum and the library itself is split into modules so that each application can choose to only bundle the parts it actually needs. At the moment, there is a module providing common components and a module providing the client. In the future, there might also be a module providing a server. Please refer to Section 4, “Requirements” to learn more about the (minimal) requirements for using EPICS Jackie.
The goal of being flexible and extensible has lead to a design of the API that focuses on the use of interfaces instead of concrete classes. This way, a user can choose to swap certain components with her own implementation if the built-in configuration options are not sufficient for a certain use case. In addition to that, components for different sub-tasks have been split into separate interfaces and classes, so that they can be used independently.
For example, the encoding and decoding of Channel Access messages is handled by a separate component, so that a user wanting to implement a special application (for example a diagnostics tool for analyzing Channel Access traffic) can use this building block.
Another example is the Channel Access name resolution (finding the
server that hosts a certain channel), which is handled by the
ChannelAccessNameResolver.
This component can also be used on its own (for example for collecting
information about channels on the network) or it can be replaced by a
custom implementation (for example an implementation that uses a central
directory service instead of using the regular name resolution protocol
built into Channel Access).
The concept of flexibility even extends to the threading model of the
Chanel Access client, which can be changed by providing a different
ClientThreadingStrategy.
Traditionally, there have been two Channel Access libraries for Java: Java Channel Access (JCA) and Channel Access for Java (CAJ). The JCA library is a thin wrapper around the C implementation of Channel Access which is used through JNI. The CAJ library, on the other hand, is a pure Java implementation, but it uses the API of JCA, which for obvious reasons has a design close to the C API. This API also has never been updated to use modern features of the Java platform like generics or the concurrency support introduced with Java 5. Besides, the CAJ library is distributed under the terms of the rather restrictive GNU General Public License.
EPICS Jackie, in contrast, has been designed using a modern API that makes use of the features introduced with Java 5 and focusing on the user’s view on channels rather than how the protocol works internally. At the same time, it is distributed under the more liberal Eclipse Public License.
On the network layer, EPICS Jackie has been carefully implemented to mimic the behavior of the C library distributed as part of EPICS Base (3.16.1). Please refer to Section 3.1, “Channel Access protocol” for details on the compatibility level.
In summary, EPICS Jackie provides a modern, pure-Java implementation of the Channel Access protocol that is distributed under a liberal license.
EPICS Jackie has been designed to be compatible with a wide range of software components, covering many software versions (including rather old ones).
EPICS Jackie implements the Channel Access protocol in the same way that the C library provided with EPICS Base 3.16.1 implements it. This includes implementation details like the timing scheme used when sending UDP packets and how the broadcast addresses for name resolution are determined when not configured explicitly.
Just like the C library since EPICS Base 3.16.1, EPICS Jackie is only compatible with Channel Access version 4.4 and newer. The current version of the Channel Access protocol (as of EPICS Base 3.16.1) is 4.13. This limitation should not have any practical impact. The oldest EPICS release publicly available (version 3.12.2 released on April 19th, 1996) already supports Channel Access version 4.6.
The EPICS Jackie client also differs slightly in how it handles connections when TCP is used for name resolution (the Channel Access protocol usually uses UDP, but TCP can be enabled explicitly): While the C implementation uses only one TCP connection when a server is both a name server and a channel server, the EPICS Jackie Client always uses separate connections for name resolution and for accessing channels. This allows for a much simpler and cleaner design of the network logic, separating tasks that are not directly related into separate components. Compared to these benefits, the overhead for maintaining an extra TCP connection is negligible. Most environments use UDP for name resolution and even if TCP is used, the number of name servers is typically low (single digit), so this not have any practical effects.
EPICS Jackie can be run on Java 6 and newer. Java 6 was chosen because it provides all the convenient language features introduced with Java 5, even adding a few improvements. As of today (May 2016), there should be virtually no platforms supporting Java 5, but not supporting Java 6. On the other hand, there are still a few supported Linux distributions that provide Java 6, but do not provide Java 7. For this reason, EPICS Jackie does not require Java 7. This might change in the future as Java 6 is being phased out in favor of more recent versions.
Please note that in order to compile EPICS Jackie from the sources, JDK 1.7 or newer is needed. The compiler from JDK 1.6 has a bug regarding multiple inheritance in interfaces. The original bug report is not available in the bug database any longer, but there are duplicates in both the Oracle JDK and OpenJDK databases. This bug has only been fixed in JDK 1.7, so the compiler from JDK 1.7 has to be used. However, the compiler’s source compatibility level is set to 1.6, so the compiled classes run inside the JVM from JDK 1.6 without any problems.
This compiler bug supposedly does not exist in some alternative compilers so that it might be possible to compile the code with the compiler from a different implementation of the Java 6 platform. However, as most users are going to use OpenJDK or Oracle JDK anyway, it was decided that it was acceptable to have other dependencies on Java 7 in the build process. In particular, this concerns the use of some Maven plugins that can only run with Java 7. This means that the Maven build process always has to run with Java 7 (or newer), but it is acceptable to specify a Java 6 only compiler in the configuration of the Apache Maven Compiler Plugin. There is no particular reason for using such a setup though. Simply running Maven with JDK 1.7 or JDK 1.8 will result in successfully compiled code that will work in the Java Virtual Machine of Java 6.
The Java archives in which the EPICS Jackie library is distributed are ready-to-use OSGi bundles, containing the required manifest. The same applies to all dependencies of EPICS Jackie, so that it can easily be deployed inside an OSGi container (for example Apache Felix or Eclipse Equinox). However, EPICS Jackie does not have any dependencies on OSGi and can thus be used outside an OSGi container without any modifications.
EPICS Jackie is a pure Java-library and is designed to run on all operating systems and architectures supporting the Java Standard Edition. There are a few places where the library makes use of platform-specific features, but neither of these are critical. In these places, the code has typically been designed to support most UNIX-like operating systems (including Linux and OS X) and Microsoft Windows.
EPICS Jackie can run in any Java run-time environment supporting Java SE 6 or newer. Its only dependency is Apache Commons Lang version 3.4 (or a newer version from the 3.x branch). Apart from this, there are no dependencies (not even a logging framework), making EPICS Jackie very light-weight.
EPICS Jackie 2.0 introduces a few new features. Unfortunately, these features could not be implemented in a way that is completely backwards compatible. However, care has been taken to make the migration as smoothly as possible and in most cases no changes to code using the library are necessary.
This release changes how the broadcast addresses for name resolution
are discovered.
This automatic discovery is typically enabled (unless the
EPICS_CA_AUTO_ADDR_LIST has been set to “NO” or the
corresponding configuration option has been disabled).
In earlier releases, all discovered broadcast addresses of the local interfaces and the local addresses of interfaces that did not have a broadcast address (e.g. point-to-point interfaces or the loop-back interface) were added to the list of addresses to use when resolving channel names.
Now, only broadcast addresses are added. No local addresses are automatically added any longer. This behavior is more consistent with the behavior of the C library. The only difference to the C library is that the destination address of point-to-point interfaces is not added to the list. This is because the Java API does offer any way to determine that address for a point-to-point interface. The loop-back address is only added when no other broadcast address could be found. Typically, this only happens if the computer does not have a regular network interface.
This change has the effect that channels provided by a local server
that is only bound to the loop-back interface are not discovered any
longer, unless the loop-back address (127.0.0.1) is explicitly added
to EPICS_CA_ADDR_LIST (or the corresponding
configuration option).
Usually, this is not a problem because an IOC will bind to all
interfaces by default and will thus be reachable through one of the
broadcast addresses automatically added to the list.
Therefore, this change in behavior should only make a difference if a
server has explicitly been restricted to the loop-back interface (e.g.
by setting EPICS_CAS_INTF_ADDR_LIST to “127.0.0.1”).
EPICS Jackie now allows setting the
echo interval.
As a consequence of this, it now honors the
EPICS_CA_CONN_TMO environment variable, while older
versions used a fixed value of 30 seconds.
Obviously this is a breaking change because in older versions, setting
this environment variable did not have any effect.
In addition to that, the constructors of three classes have been
changed so that they now take an additional parameter for this option.
In order to keep the compatibility with older code, old versions of
these constructors without the new parameter are still available.
For the configuration objects
(ChannelAccessClientConfiguration and
ChannelNameResolverConfiguration), using these
old constructors has the effect that the setting is initialized from
the EPICS_CA_CONN_TMO environment variable.
For the ChannelAccessServerConnection, using the
old constructor has the effect that the default value of 30 seconds is
used.
The old constructors have been marked as deprecated and are going to be
removed in the next major release.
The handling of the EPICS_CA_MAX_ARRAY_BYTES environment
variable has changed as well.
Starting with version 2.0, EPICS Jackie does not limit the payload size
by default.
This means that setting EPICS_CA_MAX_ARRAY_BYTES only
has an effect when also setting
EPICS_CA_AUTO_ARRAY_BYTES (see
the section called “Maximum payload size” for details).
This change is consistent with the new behavior of the C library
introduced with EPICS Base 3.16.1.
The client now sends a username and hostname to TCP name-servers. Before, it only sent that information to channel servers. This change is in accordance with the new behavior implemented by the C library of EPICS Base 3.16.1.
As a consequence of this change, the constructors of the
ChannelNameResolverConfiguration and
ChannelAccessServerConnection had to be changed.
The old constructors are still available, but they have been marked as
deprecated and are going to be removed in the next major release.
This release introduces a few changes that are useful when using
multicast packets for name resolution.
In particular, IP_MULTICAST_LOOP and
IP_MULTICAST_TTL options are set on the UDP sockets
used for name resolution (if the platform supports it).
The value of the IP_MULTICAST_TTL option can be
controlled with the EPICS_CA_MCAST_TTL environment
variable (see
the section called “Multicast time-to-live”
for details).
This change is consistent with the new features of the C library
introduced with EPICS Base 3.16.1.
As a consequence of this change, the constructor of
ChannelNameResolverConfiguration had to be
changed in order to accommodate for the new option.
The old constructor is still available, but it has been marked as
deprecated and is going to be removed in the next major release.
This release introduces a new feature called the “listener lock-policy”. This feature can help to reduce the risk of deadlocks caused by listeners acquiring a lock.
This risk of a deadlock when acquiring a lock in a listener stems from the fact that the code calling the listener also acquires an internal lock and holds it while calling the listener. The measures to reduce the risk of a deadlock consist of two parts: The first part is fully backwards compatible (and has in fact been back-ported to the 1.x branch of this software). The second part introduces a new option, namely the listener lock-policy that can be chosen by the developer using this library.
The first improvement is that the lock that is held while calling a listener is not the same lock acquired by most methods any longer. Instead, a separate lock is used for each listener. The only method also acquiring this lock is the method that removes the listener and the destroy method of the object holding the listener (only for channels and monitors). This lock is needed because it is the only way to assure that a listener is not called after the remove method has returned or the respective object has been destroyed.
Effectively, this means that the only way to cause a dead-lock is to call the remove listener method or the destroy method holding a lock that is also acquired from within the listener being removed (or any listener registered to the object in case of the destroy method). When only the listener itself calls the remove or destroy method, this is safe because it already holds the lock and thus the method will never block.
The second improvement introduces the new
ListenerLockPolicy.
By default, the BLOCK policy is used, which results
in the exact behavior described earlier.
This means that when using the BLOCK policy, the
code behaves exactly the same way as before and a deadlock might occur
when the listener takes a lock that is also held while removing the
same listener.
A different behavior is seen when choosing the
IGNORE or REPORT policy.
In this case, even removing the listener while holding a lock that is
also acquired by the same listener cannot cause a deadlock.
The price one has to pay for this is that it is no longer guaranteed
that the listener is not going to be notified after the remove listener
method has returned or the object to which the listener is registered
has been destroyed.
The difference between the IGNORE and the
REPORT policy is that the
REPORT policy causes the remove listener method to
throw a ConcurrentNotificationException
when it detects that the listener might receive one more notification.
In any case, the listener will receive at most one more notification
after the remove listener method returns, but if the policy is set to
REPORT and the remove listener method (or the
destroy method) does not throw an exception, it is guaranteed that the
listener is not going to be called again – just like when using the
BLOCK policy.
Even with these changes, having listeners that might potentially block is not without danger. By default, listeners are executed in the I/O thread and thus a listener that blocks will result in the I/O thread being blocked. Please refer to Section 5, “Listener lock-policy” and Section 6, “Threading strategy” for details.
In order to support this new feature, a few changes to the API were
necessary.
The DefaultChanneAccessClient has a number of
new constructors that accept a
ListenerLockPolicy.
The old constructors are still fully supported and a client created
with one of these constructors is going to use the
BLOCK policy, thus showing the same behavior as in
previous releases.
The ChannelAccessChannel,
ChannelAccessMonitor, and
ListenableFuture interfaces have
been extended in order to account for the new feature.
They now all have a getListenerLockPolicy()
method that returns the lock policy in use.
The AbstractChannelAccessChannel,
AbstractChannelAccessMonitor,
AbstractListenableFuture, and
DelegatingListenableFuture classes
implement this new method, so any class derived from one of these
classes automatically implements the new behavior.
However, it is necessary to change the constructor of such derived
classes if a different lock policy than BLOCK shall
be used.
Effectively, this means that most code does not have to be changed. Code simply using the Channel Access client provided by EPICS Jackie will simply work as before, but it can now choose a different listener lock-policy if desired. Only code that provides a custom implementation of one of the interfaces mentioned earlier (e.g. for tests) might have to be adapted.
The AbstractChannelAccessChannel class has a new
method failWaitForConnectionStateFutures()
that should be called by child classes when the channel is destroyed.
This method makes sure that futures returned by
waitForConnectionState(boolean) fail with an
IllegalStateException when the channel
is destroyed.
In older releases, these futures would never complete when the channel
was destroyed and thus threads waiting on these futures would block
indefinitely.
The default implementation of
ChannelAccessChannel shipped with the
library implements the new behavior, so usually no changes in code
using the library are needed.
Only custom implementations of
ChannelAccessChannel (e.g. ones that
have been created for tests) need to be updated.
The methods in the ChannelAccessValueFactory
that take an alarm severity and status have been refactored.
The signatures of the old methods were inconsistent and to some extent
confusing.
The methods with the old signatures are still available, but they have
been marked as deprecated and are going to be removed in the next major
release.
Most code should not be affected by these changes: Creating a value with an alarm severity and status typicall only makes sense on the server side, but there is no server-side implementation for EPICS Jackie yet. The most likely scenario in which existing code might already use these methods is to create values that look like they had been created by a server (e.g. for tests).
The client component is the part of the EPICS Jackie library that most users are going to use. Section 1, “Getting started” provides all the information needed to get an application running that uses the client. The subsequent sections of this chapter provide more information about how the client can be customized for a specific environment or use-case. A reader wanting to use the client is also encouraged to read Chapter IV, EPICS Jackie Common Components, Section 2, “Channel Access value objects” in order to understand how values read from or written to Channel Access channels are handled.
This section provides all the information needed for getting the first first application using the EPICS Jackie library running.
When using the Apache Maven (or a compatible) build tool, using the EPICS Jackie Client in a project is as simple as adding the following dependency to the project configuration:
<dependency>
<groupId>com.aquenos.epics.jackie</groupId>
<artifactId>epics-jackie-client</artifactId>
<version>2.0.0</version>
</dependency>
When managing dependencies manually, please make sure that the
commons-lang3-3.4.jar,
epics-jackie-client-2.0.0.jar, and
epics-jackie-client-2.0.0.jar are
included in the classpath of your project.
In order to get started, here is a very simple example that creates a client using the default configuration, reads a value, increments it by one, writes it back to the channel, and finally reads the updated value again:
import com.aquenos.epics.jackie.client.ChannelAccessChannel; import com.aquenos.epics.jackie.client.ChannelAccessClient; import com.aquenos.epics.jackie.client.DefaultChannelAccessClient; import com.aquenos.epics.jackie.common.value.ChannelAccessDouble; public class SimpleClient { public static void main(String[] args) throws Exception { ChannelAccessClient client = new DefaultChannelAccessClient(); String channelName = "testChannel"; ChannelAccessChannel channel = client.getChannel(channelName); channel.waitForConnectionState(true).get(); ChannelAccessDouble value = channel.getDouble().get(); double doubleValue = value.getValue().get(0); System.out.println("The current value is " + doubleValue + "."); channel.putDouble(doubleValue + 1.0).get(); value = channel.getDouble().get(); doubleValue = value.getValue().get(0); System.out.println("The new value is " + doubleValue + "."); channel.destroy(); client.destroy(); } }
Running this simple example program twice should result in an output similar to the following one (assuming that there is a server hosting “testChannel” on the network and that the channel is writable):
The current value is 0.0. The new value is 1.0. The current value is 1.0. The new value is 2.0.
The individual steps involved in this example are explained in greater detail in the next section.
When using the EPICS Jackie client, an application first has to create a client instance that it can then use to retrieve channels. These channel objects can then be used to perform operations on the individual channels. When they are no longer needed, channels should be destroyed. The same applies to the client instance, which should also be destroyed when it is no longer needed. A typical application, however, will retain a single client instance over the whole life-cycle of the application, only destroying it when the application is shutdown.
The client is represented by an object implementing the
ChannelAccessClient interface.
The EPICS Jackie client library provides an implementation of this
interface that is called
DefaultChannelAccessClient.
This implementation should be suitable for most applications.
ChannelAccessClient client = new DefaultChannelAccessClient();
When using the default constructor, the Channel Access client uses a
default-constructed
ChannelAccessClientConfiguration and a
DefaultClientThreadingStrategy that uses the
ErrorHandler from the
ChannelAccessClientConfiguration.
By default, the
ChannelAccessClientConfiguration initializes
itself using environment variables with the
EPICS_CA_* prefix
These are the same environment variables that are also used by the
Channel Access C library.
These defaults can be overridden by passing an explicitly constructed
ChannelAccessClientConfiguration.
There also are a few configuration options that cannot be specified
through environment variables but can only be specified by passing
them to the ChannelAccessClientConfiguration
constructor.
Please refer to Section 3, “Configuration options” for details
concerning the client configuration.
The DefaultClientThreadingStrategy in its
default configuration should be suitable for most use-cases.
However, it is possible to modify some behavior by constructing it
explicitly and specifying certain options.
In the rare case that these customization options are not sufficient,
it is even possible to use a custom implementation of the
ClientThreadingStrategy.
Please refer to Section 6, “Threading strategy” for details
concerning the threading strategy.
The ChannelAccessClient is thread-safe.
This means that a single instance is typically sufficient for the
whole application.
In fact, sharing a single instance actually help to save system
resources.
The only reason for using more than one instance in the same
application is when it is necessary to have clients that use different
configurations.
After the client has been constructed, channels can be created. For example, we can create a reference to a channel named “testChannel” like this:
ChannelAccessChannel channel = client.getChannel("testChannel");
Each time a channel is requested from the client, a new instance of
ChannelAccessChannel is returned.
However, all instances referring to the same channel name internally
use the same implementation so that the overhead for maintaining
several instances is negligible.
This concept facilitates the use of a single client for a whole
application because a component can request a channel without having
to worry whether another component has requested the same channel.
This resource sharing is implicitly handled by the library and
completely transparent to the user.
Like the ChannelAccessClient, instances
of ChannelAccessChannel are
thread-safe.
When a channel is created, the new channel object is returned immediately without blocking for network I/O. However, the client starts a name-lookup process for the specified channel name in the background. When the server hosting the channel is found, the client automatically connects to this server and subsequently to the channel. When the client is already connected to a channel hosted by the same server, the existing connection is reused instead of establishing a new one. In any case, once the channel has been successfully connected, the respective channel object changes to the connected state. When, at some later point, the connection is interrupted (for example because of a general network interruption or because the server is stopped), the channel object changes to the disconnected state and the client starts the lookup process again. Once the (new) server for the channel is found, the connection to the server is established again and the channel changes to the connected state once again.
This whole process is transparent to the user of the client.
The ChannelAccessChannel object remains
valid over the whole life-cycle until it is explicitly destroyed by
the user.
However, read or write operations fail while a channel is not
connected and monitor subscriptions do not receive updates.
For this reason, the user might be interested in knowing the channel’s
connection state.
The easiest way of learning the channel’s connection state is by
calling the isConnected method:
if (channel.isConnected()) { System.out.println("The channel is connected."); } else { System.out.println("The channel is not connected."); }
However, when we are interested in waiting for the channel to be connected, this method is not very useful because using it would involve inefficient polling. Instead, there are two more efficient ways to wait for a certain connection state. The first one involves waiting for a future and the second one registers a listener. Waiting for a future is more suitable when we just want to wait once, while using a connection listener is better when we want to be informed of all connection-state changes.
We can wait for the channel to be connected just once like this:
try { channel.waitForConnectionState(true).get(); System.out.println("The channel is now connected."); } catch (ExecutionException e) { e.printStackTrace(); } catch (InterruptedException e) { Thread.currentThread().interrupt(); }
If we wanted to wait for the channel to be disconnected once, we
would pass false instead of
true to the
waitForConnectionState method.
The future returned by
waitForConnectionState implements
ListenableFuture.
This means that we do not have to block in order to wait for the
future to complete.
Instead, we can register a listener that is notified
asynchronously when the future completes.
Actually, this applies to all methods of the EPICS Jackie Client
that return a future.
These futures always are instances of
ListenableFuture and can thus be used
with listeners.
In order to register a listener, we first create the future and then add the listener to it:
ListenableFuture<Boolean> waitForConnectionStateFuture = channel
.waitForConnectionState(true);
waitForConnectionStateFuture
.addCompletionListener(new FutureCompletionListener<Boolean>() {
@Override
public void completed(ListenableFuture<? extends Boolean> future) {
try {
future.get();
System.out.println("The channel is connected now.");
} catch (ExecutionException e) {
e.printStackTrace();
} catch (InterruptedException e) {
throw new RuntimeException(
"Unexpected InterruptedException.");
}
}
});
The completion listener is notified when the future completes.
If the future represents the result of a successful operation, the
value returned by its get method represents
the result of the operation.
In this example, this value is the connection state
(true for connected, false for
disconnected).
If the future represents a failed operation, the future’s
get method throws an
ExecutionException that wraps the
cause of the execution failure.
An InterruptedException is only
thrown when the thread blocked in order to wait for the future to
complete and was interrupted before the future completed.
As the future has already completed when the listener is notified,
such an exception does not have to be expected.
A listener registered with a future must not block or perform long running operations. Typically, such a listener is executed in the thread that completes the future. For a future that represents the connection state, this is most likely the I/O thread associated with the server hosting the channel. When the listener blocks, this will bring the whole thread to a halt, stopping any I/O from happening. Depending on the blocking action, this could even lead to a dead lock when the action the listener is waiting for would actually need to perform I/O operations in order to finish.
While the user is strongly discouraged from performing blocking operations in listeners, there is a way to protect the client from being stalled. Please refer to Section 6, “Threading strategy” for details.
Even a simple blocking action, that usually finishes quickly, like acquiring a lock, can be dangerous. Please refer to Section 5, “Listener lock-policy” for details.
The alternative way of being notified when the channel is connected
(or disconnected) is through a
ChannelAccessConnectionListener that
is notified every time when the channel changes its connection
state:
channel.addConnectionListener(new ChannelAccessConnectionListener() { @Override public void connectionStateChanged(ChannelAccessChannel channel, boolean nowConnected) { if (nowConnected) { System.out.println("Channel " + channel.getName() + " connected."); } else { System.out.println("Channel " + channel.getName() + " disconnected."); } } });
Directly after being registered, the listener is called once with the current connection state and after that once for every change of the connection state.
Like future listeners, connection listeners must not block unless specific precautions have been taken. Please refer to Section 5, “Listener lock-policy” and Section 6, “Threading strategy” for details.
![[Note]](docbook/images/note.png) | Note |
|---|---|
In the default implementation of the Channel Access client, the client does not keep a strong reference to a channel. This means that a channel will eventually be marked for garbage collection and destroyed if the application does not retain a strong reference to it. This happens even if there are active connection listeners attached to the channel.
However, if possible, an application should not rely solely on
garbage collection for resource management because garbage
collection is inherently unpredictable.
The application should call the channel’s
The automatic destruction during garbage collection is only intended as a last resort in case a bug in the application would otherwise cause a resource leak, very similarly to how the Java platform manages I/O resources. Please refer to Section 2.8, “Resource management” for more information about resource management in the EPICS Jackie Client. |
The Channel Access protocol provides a “get” operation that can be used to read the current value of a channel just once. This operation should not be used if continuous updates of a channel’s value are desired. For this use-case, Channel Access provides much more efficient “monitor subscription” (see Section 2.6, “Using monitor subscriptions”).
It is an inherent feature of the Channel Access protocol that the type of a channel cannot be known a priori. For this reason, there are two options for getting a channel’s value: The request can be made using the native type of the channel, that can only be determined at run-time. Alternatively, the request can be made using a specific type. In this case, the server will convert the channel’s value to the requested type before sending it to the client.
First, we look at an example where we specify a specific data-type:
try { ChannelAccessDouble value = channel.getDouble().get(); System.out.println("The channel has the value " + value.getValue().get(0) + "."); } catch (ExecutionException e) { e.printStackTrace(); } catch (InterruptedException e) { Thread.currentThread().interrupt(); }
As we specified that we want to get a value of type
DBR_DOUBLE (by using the
getDouble method), we know at compile time
that we will get a value of type
ChannelAccessDouble.
Actually, the type of the return value is
ChannelAccessSimpleOnlyDouble, but that
interface does not offer any additional methods, so we can simply
treat it like a ChannelAccessDouble for
now.
The getDouble method does not return the
value directly.
Reading a channel's value requires network I/O, so the operation can
not complete right away.
Instead of blocking, the getDouble method
returns a listenable future that completes when the value has been
read (or the operation has failed).
Like we have already seen in
the section called “Waiting using a future”, we can block,
waiting for the future to complete, or we can register a listener that
is notified when the future has completed.
The get… methods of
ChannelAccessChannel return sub-types
of ChannelAccessValue instead of
returning a primitive (or an array thereof) directly.
There are two reasons for this:
First, these values fit in the same type hierarchy that is also used
when the actual type is determined at run-time.
This makes the code more generic.
Second, depending on the type, the values may carry additional
information like the channel’s alarm state or a time stamp.
The value’s getValue method returns a
DoubleBuffer instead of a
double[] array.
This way, the same value may be shared by different components of an
application without having to worry that one component might
accidentally modify the value, leading to undesired or even undefined
behavior.
As an alternative, values could be copied whenever they are passed to
more than one component, but this would be very inefficient,
in particular when large arrays are involved.
Each of the channel’s get… methods has to
variants:
The first one takes an integer parameter.
This parameter specifies the maximum number of array elements that are
read from the server.
If the channel’s value is represented by an array with more elements,
the remaining elements are simply skipped.
The second variant does not take any parameters.
It always returns all the elements, regardless of the array’s size.
There are two get… methods for each of the
data types defined in ChannelAccessValueType,
the only exception being the DBR_PUT_ACKT and
DBR_PUT_ACKS types which can only be used in put
operations.
For each of the seven basic types (DBR_STRING,
DBR_SHORT, DBR_FLOAT,
DBR_ENUM, DBR_CHAR,
DBR_LONG, and DBR_DOUBLE), there
are sub-types that provide the alarm status
(DBR_STS_…), the time stamp and alarm status
(DBR_TIME_…), the alarm status and display
information (DBR_GR_…), and the alarm status,
display information and control limits
(DBR_CTRL_…).
In addition to that, there are two special types,
DBR_STSACK_STRING and
DBR_CLASS_NAME.
The DBR_STSACK_STRING type (method
getAlarmAcknowledgementStatus) is used to
get information about acknowledged and unacknowledged alarms and the
configuration regarding the acknowledgement of transient alarms.
The DBR_CLASS_NAME type (method
getClassName) is used to get the name of the
implementation backing the channel. For a regular EPICS IOC, this is
the name of the record type (for example ai,
ao, bi, bo,
calc, longin, or
longout).
If we do not want to get a value of a specific type, but rather want
to use the type that is native to the server, we can use the channel’s
getNative method.
There also is a get method taking a parameter
of type ChannelAccessValueType.
It can be used when a specific type shall be requested but this type
is not known at compile-time.
For example, an application might be interested in getting a value
with the type native to the server, but also wants a time stamp. In
this case, the application can use the channel's
getNativeDataType to determine the native
type and than use the corresponding type that also includes a time
stamp:
ChannelAccessValueType nativeType = channel.getNativeDataType(); ChannelAccessValueType timeType; try { timeType = nativeType.toTimeType(); } catch (IllegalArgumentException e) { timeType = ChannelAccessValueType.DBR_TIME_STRING; } try { ChannelAccessGettableValue<?> value = channel.get(timeType).get(); ChannelAccessTimeValue<?> timeValue = (ChannelAccessTimeValue<?>) value; System.out.println("Time stamp is " + timeValue.getTimeStamp().toString()); } catch (ExecutionException e) { e.printStackTrace(); } catch (InterruptedException e) { Thread.currentThread().interrupt(); }
As the exact type cannot be known at compile time, the
get method returns a future that in turn
returns a value of type
ChannelAccessGettableValue.
This is the base type implemented by all values that can be returned
by read operations.
In this example, we can safely cast the value to
ChannelAccessTimeValue because we
requested a DBR_TIME_… type, so the returned value
must implement ChannelAccessTimeValue.
The ChannelAccessValue interface
provides a method getType that can be used to
determine the actual type of a value at run-time.
There also is a getGenericValueElement method
that can be used to retrieve an element of the value array (specifying
the element’s index) without having to know its actual type.
Combined with the getValueSize method, this
can be used to get all the value elements without knowing their
concrete type.
However, this involves boxing of primitive values to turn them into
objects, making this much less efficient than casting to the correct
type and then using the getValue method to
get a buffer providing primitives.
Please note that the getNativeDataType method
(like the get… methods) can only be used
when the channel is connected.
Using it when the channel is not connected results in an
IllegalStateException being thrown.
The get… methods do not throw an
IllegalStateException.
Instead, the returned future’s get method
throws a ChannelAccessException with a
status of ECA_DISCONN.
For writing to a channel, the Channel Access protocol provides a “put” operation. Writing a value is very similar to reading one. For example, in order to write a double value, we could use the following code:
try { // The get() call on the future is only necessary if we want to wait for the // operation to complete or if we want to be notified if it fails. channel.putDouble(42.0).get(); } catch (ExecutionException e) { e.printStackTrace(); } catch (InterruptedException e) { Thread.currentThread().interrupt(); }
Like a read operation, a
write operation completes asynchronously.
The ListenableFuture returned by the
put… method can be used to wait for the
operation to be completed or to register a listener that is notified
when the operation has completed.
If we are not interested in waiting for the operation to complete, we
can simply ignore the returned future.
In this case, however, we will not be notified either when the
operation fails.
If we are interested in knowing whether the operation has been
successful, we have to call the future’s get
method (which will block when the future has not completed yet).
This method returns null on success and throws an
exception on failure.
The ChannelAccessChannel has two
put… methods for each of the seven basic
data-types described by ChannelAccessValueType
(DBR_STRING, DBR_SHORT,
DBR_FLOAT, DBR_ENUM,
DBR_CHAR, DBR_LONG, and
DBR_DOUBLE).
For each data type, there is one method taking a single element and
one taking an array of elements (for example
double and double[]).
The DBR_STRING type is an exception because there
is an additional method taking a Collection of
Strings.
Writing values of a “complex” type (for example a
DBR_GR_STRING) is not supported by the Channel
Access protocol.
However, there are two special types, that can only be used in write,
but not in read operations:
DBR_PUT_ACKT and DBR_PUT_ACKS.
The first one is used for configuring whether transient alarms need
to be acknowledged and can be written by using the channel’s
putConfigureAcknowledgeTransientAlarms
method.
The second one is used for acknowledging alarms and can be written by
using the channel’s putAcknowledgeAlarm
method.
It is also possible to write a value of a type that is only determined
at run-time.
The channel’s put method takes a parameter of
type ChannelAccessPuttableValue.
This is a marker interface that is only implemented by types that may
be used in write operations.
An application must never attempt to supply its own implementation of
any of the interfaces in the
ChannelAccessValue type hierarchy.
Instead, one of the methods provided by
ChannelAccessValueFactory should be used to
construct an instance.
Please refer to Chapter IV, EPICS Jackie Common Components,
Section 2, “Channel Access value objects” for more information about the
Channel Access value type system.
Please note that the the put… methods can
only be used when the channel is connected.
When it is used while the channel is not connected (or when the
channel disconnects before the operation has finished) the future
returned by the put… method throws a
ChannelAccessException with a status of
ECA_DISCONN.
The Channel Access protocol has a very useful feature called “monitors”. These monitors can be used to be notified by a server whenever a channel’s state or value changes (significantly). This works asynchronously so that it is much more efficient than polling the channel. This helps to reduce latency and to preserve processing power, I/O operations, and bandwidth.
Creating a monitor subscription is very similar to reading from a channel. Monitor subscriptions support exactly the same data types that are also supported for read operations. For example, the following code shows how we can create a monitor subscription for double values that include a time stamp:
ChannelAccessMonitor<ChannelAccessSimpleOnlyDouble> monitor = channel
.monitorDouble();
monitor.addMonitorListener(
new ChannelAccessMonitorListener<ChannelAccessDouble>() {
@Override
public void monitorError(
ChannelAccessMonitor<? extends ChannelAccessDouble> monitor,
ChannelAccessStatus status, String message) {
System.out.println("Error: " + status.toString()
+ (message == null ? "" : ", " + message));
}
@Override
public void monitorEvent(
ChannelAccessMonitor<? extends ChannelAccessDouble> monitor,
ChannelAccessDouble value) {
System.out.println("Value is " + value.getValue().get(0));
}
});
Monitor subscriptions differ from read operations in three ways:
First, they can always be created, even when the channel is
disconnected.
Of course, events are only received as long as the channel is actually
connected.
Second, the monitor… methods return a
ChannelAccessMonitor instead of a
ListenableFuture.
Third, a monitor subscription does not cause just one event, but it
causes one event after the monitor is created and one event every
time an event is received from the server.
The ChannelAccessMonitorListener has
two methods.
The monitorError method is called when the
server sends an error notification.
Typically, a server only sends an error notification when the monitor
subscription could not be created for some reason.
When the channel is disconnected, this does not cause an error
notification because this is not considered a problem:
As long as a monitor exists, it will automatically start sending
events once the channel is (re-)connected.
The monitorEvent method is called every time
when an updated value is received from the server. This method is also
called once after the monitor subscription has been created (and the
first value has been received from the server).
It is also called once after the connection with the server has been
reestablished because the value on the server might have changed in
the meantime.
| Note |
|---|---|
In the default implementation of the Channel Access client, the client does not keep a strong reference to a monitor. This means that a monitor will eventually be marked for garbage collection and destroyed if the application does not retain a strong reference to it. This happens even if there are active listeners attached to the monitor.
However, if possible, an application should not rely solely on
garbage collection for resource management because garbage
collection is inherently unpredictable.
The application should call the monitor’s
The automatic destruction during garbage collection is only intended as a last resort in case a bug in the application would otherwise cause a resource leak, very similarly to how the Java platform manages I/O resources. Please refer to Section 2.8, “Resource management” for more information about resource management in the EPICS Jackie Client. |
For each get… method of the
ChannelAccessChannel, there are two
corresponding monitor… methods. One of them
has the same parameters as the corresponding
get… method.
The other one takes an additional parameter of type
ChannelAccessEventMask.
This parameter defines the kind of events for which the server should
send a notification.
If not specified, the default event mask specified in the
ChannelAccessClientConfiguration for the client
is used.
There are four basic mask values (DBE_VALUE,
DBE_ARCHIVE, DBE_ALARM, and
DBE_PROPERTY).
These mask values can be combined to build other masks.
DBE_VALUE is used for retrieving notifications when
the channel’s value changes.
DBE_ARCHIVE is also used for notifications on value
change, but a server can choose to use a larger dead-band compared to
the one used for DBE_VALUE. This means that
typically, only larger value changes (that are considered significant
enough to be archived) result in a notification.
Usually, only one of DBE_VALUE or
DBE_ARCHIVE are specified in a mask.
DBE_ALARM is used for being notified whenever a
channel’s alarm state changes.
DBE_PROPERTY is used for being notified when other
properties of a channel (for example engineering units or limits)
change.
The default mask is the combination (binary or) of
DBE_VALUE and DBE_ALARM.
Like when reading values, the type that is supposed to be used for a
monitor subscription cannot always be determined at compile-time.
For these cases, the
ChannelAccessChannel provides the
monitorNative and
monitor methods.
The monitorNative methods create a monitor
that always delivers values with the type that is native to the
server.
As a channel might be disconnected and reconnected to a different
server (or the same server using a different configuration), the
native type can change over the life-time of the monitor subscription.
In this case, the type of the values delivered with monitor events
will change accordingly, always representing the current native type.
The monitor method allows the user to specify
the data type of the value that the server shall send with monitor
events.
This must be one of the types that is allowed for a read operation.
Please refer to Section 2.4, “Reading from a channel” for details
about specifying the data type for a read operation at run-time.
The Channel Access protocol allows a server to restrict access to a channel. There can be separate access restrictions for read and write operations. For example, a server might choose to allow read access to all clients but restrict write access to certain clients.
An application can query the access rights for a channel by using the
ChannelAccessChannel’s
isMayRead and
isMayWrite method.
The first one returns true if read operations (this
means “get” and “monitor” operations) are allowed, the second one
returns true if write (“put”) operations are allowed.
The access rights can only be checked when the channel is connected.
Calling either of the methods when the channel is disconnected results
in an IllegalStateException being
thrown. Please note that when a channel is connected, then
disconnected, and then connected again, the access rights might have
changed compared to the first connection because the channel might now
be hosted by a different server (or the same server, but using a
different configuration).
Calling one of the get… or
put… methods when the client does not have
the corresponding access right results in the future returned by the
method failing with a
ChannelAccessException that has a
status code of ECA_NORDACCESS or
ECA_NOWTACCESS respectively.
In the same way, a monitor triggers an error notification with a
status code of ECA_NORDACCESS when a monitor
subscription cannot be created because of insufficient access rights.
The objects provided by the EPICS Jackie Client (the
ChannelAccessChannels, the
ChannelAccessMonitors, or even the
ChannelAccessClient itself), are
associated with network resources.
For this reason, it is important that these objects are destroyed so
that the corresponding network resources can be deleted when they are
not needed any longer.
Each of these objects can be destroyed by calling its
destroy method. Destroying a channel also
destroys all its monitors and destroying a client also destroys all
its channels.
Each time the ChannelAccessClient’s
getChannel method is called, a separate
ChannelAccessChannel instance is
returned.
Even though the resources of all the instances are shared internally,
thus avoiding the redundant allocation of resources, each instance is
destroyed separately.
This means that the resources are only realeased after
all instances of
ChannelAccessChannel referring to the
same channel name have been destroyed.
The same applies to
ChannelAccessMonitors.
Each time one of the monitor… methods is
called, a new instance is returned.
However, those instances internally share resources.
This means that several monitor’s created for the same channel name
and using the same parameters (monitor event mask, data type, and
element count) internally use only one subscription.
This subscription is cancelled when the last monitor referring to it
is destroyed.
In order to avoid a resource leak when an application erroneously does
not destroy a channel or monitor when it does not need it any longer,
the default implementation
(DefaultChannelAccessClient) does not keep
strong references to channels and monitors.
This means that a channel or monitor that is not referenced any
longer will eventually be marked for garbage collection and destroyed.
For this reason, it is important that application code wanting to keep
a channel or monitor alive (typically because it has a listener
attached to it and wants to keep getting notified of events) has to
retain a strong reference to the channel or monitor.
For example, the following code will not work as naively expected:
ChannelAccessMonitorListener listener = ... // The details of the listener are // not relevant for this example. // Bad example, do NOT write code like this: channel.monitorDouble().addMonitorListener(listener);
First, the monitor listener might receive events as expected.
After some time, however, the Java Virtual Machine might run the
garbage collection, resulting in the monitor instance created by
monitorDouble being destroyed because there
is no strong reference to it.
Still, an application should not solely rely on garbage collection for
destroying channels or monitors.
Typically, the Java Virtual Machine initiates a garbage collection
when there is demand for it because free memory is becoming scarce.
However, channels and monitors not only consume memory, but also
consume precious network and I/O resources (for example file
descriptors).
This means that there could be a situation in which these resource
become scarce, but the garbage collection does not run because free
memory is still abundant.
This is the same reason why Java I/O objects (for example
InputStream or
OutputStream) should be closed explicitly
instead of relying on garbage collection closing them.
When a strong reference to a monitor is kept, it is not necessary to
also keep a strong reference to the corresponding channel.
Each monitor keeps a strong reference to its channel (which can be
retrieved using the getChannel method).
For this reason, a channel will only be destroyed by the garbage
collection after all monitors referencing it have been destroyed.
As a general guideline, an application should keep a separate channel
or monitor instance for each of its components, even if they refer to
the same channel.
As described earlier, the
ChannelAccessClient ensures internal
sharing of resources so that the overhead is negligible.
The resource management is simplified significantly by this approach:
A component can create the channel or monitor when the component is
created and destroy it when the component is destroyed.
For example, an application with a graphical user-interface (GUI)
might have widgets that refer to channels for displaying purposes.
In this case, it makes sense that each of these widgets has its own
instance of ChannelAccessChannel.
When a widget is destroyed, it can safely destroy its associated
channel.
This means, for example, that a window being closed would destroy all
the widgets used in this window and thus indirectly all the channel
instances.
If the same channels were also used in other windows, the internal
resources would be kept alive and thus the other widgets would
continue working as expected.
However, when the last window referencing a certain channel was
closed, this would result in the immediate destruction of the last
ChannelAccessChannel instance, thus
immediately freeing the associated resources.
Basically, the same applies to instances of
ChannelAccessClient.
When a client is not needed any longer, it should be destroyed.
However, most applications will need the client for their whole
life-time.
When the Java Virtual Machine is shutdown, the resources associated
with a client are released implicitly, making it not strictly
necessary to destroy the client.
However, it is still considered good style to destroy the client
explicitly when reasonably possible.
Having more than one client instance per application should be avoided
at all cost.
Each client instance consumes precious resources (network sockets and
background threads), so operation is most efficient when there is only
one client.
In addition to that, the sharing of resources for channels and
monitors is realized on the client level.
This means that if there is more than one client and each of these
clients creates a channel instance referring to the same channel name,
those channel instances will not share resources, increasing resource
consumption significantly.
In case of doubt, it is better to only have a single client instance
and not being able to properly destroy the client than creating many
client instances just for the sake of simpler resource management.
The ChannelAccessClient can be configured
by supplying an instance of
ChannelAccessClientConfiguration.
Instances of ChannelAccessClientConfiguration are
immutable, so all configuration parameters have to be passed to the
constructor.
The parameter-less constructor initializes all configuration parameters
with default values.
When using the explicit constructor, it is possible to only specify a
few parameters explicitly.
Specifying null for the other parameters has the
effect of initializing them with their default values.
In addition to the parameters that can be set directly in the client
configuration, the client configuration contains an instance of
BeaconDetectorConfiguration and an instance of
ChannelNameResolverConfiguration.
As far as the user is concerned, these configuration objects can simply
be considered a part of the client configuration.
They are only separated into separate classes because they provide the
configuration for separate components that in this way can avoid any
dependency on the general client configuration.
Like the ChannelAccessClientConfiguration,
instances of these classes are immutable and configuration parameters
have to be specified when constructing the object.
Like the client configuration, they both have a default constructor that
specifies null for all parameters, thus setting them
to their default values.
The ChannelAccessClientConfiguration is the top
object in the configuration hierarchy used by the
ChannelAccessClient. It encapsulates
all the configuration options needed by a client, including an
instance of BeaconDetecorConfiguration
(explained in Section 3.2, “Beacon detector configuration”)
and an instance of
ChannelNameResolverConfiguration (explained in
Section 3.3, “Channel-name resolver configuration”).
The configured character set is used whenever string data is received from the network or sent to the network. This obviously concerns string values, but other values that carry strings in their meta-data (for example the engineering units) and textual error messages sent over the network are affected as well.
The character set specified for the
ChannelAccessClientConfiguration is also used
by the ChannelNameResolverConfiguration
(see Section 3.3, “Channel-name resolver configuration”)
unless a ChannelNameResolverConfiguration is
specified when creating the
ChannelAccessClientConfiguration.
If not specified, the UTF-8 character set is used. In the unlikely event that the UTF-8 character set is not available (it should always be available because it is one of the standard character sets supported by the Java Standard Edition), the platform’s default character set is used.
The host name is sent to each server when a connection is established. Some servers use the host name in order to decide which access rights (see Section 2.7, “Access restrictions”) should be granted to the client. The host name sent to the server usually is the unqualified host-name (without a domain part).
If not specified explicitly, the host name is determined
automatically.
Unfortunately, the Java platform specifies no standardized way for
reliably determining the host name.
For this reason, a multi-step process is used.
First, the library tries to call the hostname
command and uses its output.
If this command is not available or returns with an error, a
platform-specific environment variable (HOSTNAME on
UNIX-like systems, COMPUTERNAME on Windows systems)
is used.
If this environment variable is not set either, the library tries to
determine the hostname through DNS (by calling
InetAddress.getLocalHost().getHostName()).
If this fails as well, the library uses the string
“<unknown host>” as the host name.
Typically, this setting is chosen so that is has the same value as the corresponding setting in the channel-name resolver configuration.
The user name is sent to each server when a connection is established. Some servers use the user name in order to decide which access rights (see Section 2.7, “Access restrictions”) should be granted to the client.
If not specified explicitly, the user name is determined
automatically.
Unfortunately, the Java platform specifies no standardized way for
reliably determining the user name.
For this reason, a multi-step process is used.
First, the library tries to use platform-dependent classes from the
com.sun.security.auth.module package.
If these classes are not available (they are not part of the Java
Standard Edition but are only bundled with certain Java run-time
environments) or their use results in an exception, the
user.name system property is used.
If this property is not set, the USERNAME environment
variable is used.
If this environment variable is not set either, the library uses the
empty string as the user name.
Typically, this setting is chosen so that is has the same value as the corresponding setting in the channel-name resolver configuration.
The Channel Access protocol works through the exchange of messages. Some of these messages (in particular the ones transporting values for “get”, “put”, and “monitor” operations) have a payload. The size of this payload (and thus the total message size because the header has a fixed size-limit) can be limited. The reason for limiting the payload size is the fact that a received messages has to be buffered completely before it can be decoded. In the same way, a message that is sent is typically completely serialized to a buffer before being sent.
When choosing a large maximum payload size, the potential memory consumption for these buffers increases. When choosing a small maximum payload size, this has the effect that larger messages cannot be sent or received, limiting the maximum number of elements that the value array for a “put” operation (send limit) or the value array for a “get” or “monitor” operation (receive limit) can contain.
Changing the limit on the client side is only effective when the server uses the same or greater limits. If the client uses greater limits than the server, the limits set by the server will effectively limit the maximum size of the payload.
If not configured explicitly, the library does not limit the
payload size (except for the technical limit described in the next
paragraph).
However, if the EPICS_AUTO_ARRAY_BYTES environment
variable is set to “NO” (case-insensitive), the value of the
EPICS_CA_MAX_ARRAY_BYTES environment variable is
used for both the send and receive limit.
If that environment variable is not set, a default value of 16384
bytes is used.
This value is also the minimum payload size that can be set.
The C library from EPICS Base uses the same two environment
variables since EPICS Base 3.16.1.
Before EPICS Base 3.16.1, the C library did not consider the
EPICS_CA_AUTO_ARRAY_BYTES and always acted like that
environment variable was set to “NO”.
While the Channel Access protocol in theory allows for payload sizes just short of 4 GB, restrictions imposed by the implementation used in the EPICS Jackie library limit it to slightly less than 2 GB. However, this should not have any practical consequences because the Channel Access protocol is in no way designed to handle large amounts of data efficiently and when values significantly larger than a few megabytes have to be transferred, using a different communication protocol should be considered.
The echo interval is the time between sending two echo requests to
a server.
Echo requests are sent in order to ensure that the connection is
still working.
If a beacon packet from the same server is received within this
interval, this is considered proof that the network connection is
okay and thus no echo request is sent .
For this reason, this setting should be chosen to be at least two
times as large as the max. interval between sending two beacons.
The beacon interval is configured on the server-side (typically by
setting the EPICS_CA_BEACON_PERIOD environment
variable).
Echo requests are sent for two reasons: First, it allows the client to detect when the network connection has been interrupted and the corresponding channels should be put into the disconnected state. This way, the disconnected state is visible early, even before the operating system closes the TCP socket. Second, sending some data might help the operating system to detect that a TCP connection has been interrupted, thus giving the client a chance to eventually establish a new connection (potentially with a different server now serving the channels).
Typically, this setting is chosen so that is has the same value as the corresponding setting in the channel-name resolver configuration.
If this option is not specified, the value of the
EPICS_CA_CONN_TMO environment variable is
used.
This is the same environment variable that is also used by the C
library.
If the environment variable is not set, the default value of 30
seconds is used.
The minimum interval that can be set is 0.1 seconds.
The default event mask is used when a monitor subscription is
created (see Section 2.6, “Using monitor subscriptions”) and no event
mask is specified when calling the channel’s
monitor… method.
If this configuration value is not specified explicitly, a
combination of DBE_VALUE and
DBE_ALARM (binary or) is used as the default
value.
The CID block reuse time is specified in milliseconds and defines how long a channel identifier (CID) is blocked from being reused after it has been released.
The CID is a 32-bit integer number that is internally used in the protocol for identifying a certain channel in the communication between client and server. The client assigns a CID when it creates the channel and (aside from other places) uses it in the name-lookup process. The responses received in reply to a name-lookup request only contain the CID, not the channel name. This means that the CID is the only way by which the client can map the response to a channel name.
As name resolution is typically done through the UDP protocol, involving broadcast messages being sent into the network, there is no reliable way of determining when the last response for a certain request has been received. This means that if a CID is reused too early, a response that actually belongs to an earlier request but arrives late (possibly because of a slow server or a high-latency network link) could be wrongly correlated with a more recent request specifying a different channel name.
On the other hand, if the CID block reuse time is chosen too large, this can have the undesirable effect of an increased memory consumption (for maintaining the list of not-yet reusable CIDs) or (in the worst case) even resource exhaustion because of a lack of free CIDs.
If the time is chosen reasonably, this scenario is very unlikely and limited to a scenario in which a client application creates and destroys channels at an unreasonably high rate.
In general, there is no need for an application to modify this value. The default value of 900,000 milliseconds (15 minutes) ensures that late replies do not pose any danger, even in the presence of very slow servers and high-latency links. On the other hand, this interval is so short that a client would need to create and destroy channels at a rate of more than one thousand per second to cause a significant memory footprint.
The error handler used by the client is also specified through the
ChannelAccessClientConfiguration. However,
its details are described in
Section 4, “Error handling”.
In most environments, the name resolution of channel names relies on UDP broadcast packets being sent to the network. In order to avoid flooding the network with these brodcast packets, a complex algorithm is used that limits the rate of name resolution requests. While the details of this algorithm are rather complex, one of its main effects is that the time interval between two resolution requests for the same channel name is increased with every failed attempt to resolve it. This has the effect that a channel name that can never be resolved (maybe because it has been mistyped) will still not put a significant load on the network. However, there is the undesired side effect that a channel that could not be resolved because its server was offline might take a very long time to be resolved after the server goes online. In order to mitigate this effect, there is a mechanism that (under certain circumstances) can detect when a server that has previously been offline becomes available. This mechanism is called “beacon detection” and works by decreasing the search interval for channels that could not be resolved for a long time when a “beacon anomaly” (an event that might indicate a previously offline server now being online) is detected.
The whole beacon detection and name resolution process is transparent
to the user and the client internally handles it.
However, there are a few configuration options regarding the beacon
detection that can be configured in the
BeaconDetectorConfiguration.
Typically, the default values of this configuration are fine, an
application only has to specify explicit values if it wants to
override the default behavior of how the port numbers are determined.
The default server port is the port number on which a server sending a beacon message is assumed to accept name-resolution requests. Newer servers typically include this information in a beacon message, but older servers might not. In this case, the port number specified through this option is used. The default implementations of the Channel Access client and name resolver provided by the EPICS Jackie library do not use this information, even if it is supplied by the server. For this reason, there is typically no need for an application to modify this setting.
If not specified explicitly, this setting is initialized with the
value of the EPICS_CA_SERVER_PORT environment
variable.
If this environment variable is not set, the protocol’s default port
number (5064) is used.
The beacon detection mechanism relies on the reception of beacon messages sent in UDP broadcast packets. The repeater port is the port on which these broadcast packets are received. The name stems from the fact that there is typically a process called the “repeater” which listens for these packets and forwards them to the various clients running on the same host. Typically, the repeater is started automatically when the first Channel Access client application is started and runs in the background.
The DefaultBeaconDetector from the EPICS
Jackie library first tries to connect to an existing repeater so
that it can be notied when the repeater receives a beacon message.
If it determines that there is no repeater running yet, it tries to
start it.
If the repeater cannot be started (typically because there is no
EPICS Base installation available or it is not in the system path),
it starts its own repeater inside the Java Virtual Machine (JVM).
The repeater from EPICS Base is preferred over the one bundled with
EPICS Jackie because other clients, that are started later, might
rely on the existing repeater process and the repeater started
inside the JVM is stopped when the JVM is shutdown while the
external repeater process is typically kept alive.
If not specified explicitly, the value of the
EPICS_CA_REPEATER_PORT environment variable is used
as the repeater port.
This is the same environment variable that is also used by the C library.
If this environment variable is not set, the protocol’s default
value (5065) is used.
The error handler is used by the beacon detector to log errors that occur during its operation. For details, please refer to Section 4, “Error handling”.
The channel-name resolver is responsible for resolving channel names. This is the process of finding the server that hosts the channel identified by a certain name. The channel-name resolver is a vital part of the Channel Access client because without it, the client could not know which server(s) it has to connect to or whether a channel even exists at all.
In most environments, UDP is used for name resolution. In very recent protocol versions (since Channel Access version 4.12, introduced with EPICS Base 3.14.12 released in November 2010), name resolution via TCP is supported as well. However, unlike the name resolution via UDP, name resolution via TCP always requires explicit configuration (at least by setting the corresponding environment variable).
The behavior of the channel-name resolver (in particular the port
numbers used) can be specified by explicitly constructing a
ChannelNameResolverConfiguration and passing it
to the ChannelAccessClientConfiguration.
The configured character set is used when serializing channel names in order to send them over the network inside search requests.
When the ChannelNameResolverConfiguration is
created automatically by the
ChannelAccessClientConfiguration (because
no ChannelNameResolverConfiguration has been
specified), it always uses the same character set as the surrounding
ChannelAccessClientConfiguration.
When creating the
ChannelNameResolverConfiguration explicitly,
it is possible to specify a different character set then the one
used by the ChannelAccessClientConfiguration.
However, in most scenarios, using different character sets does not
make sense.
If this option is not specified, the UTF-8 character set is used. In the unlikely event that the UTF-8 character set is not available (it should always be available because it is one of the standard character sets supported by the Java Standard Edition), the platform’s default character set is used.
The host name is sent to each TCP-based name-server when a connection is established. Some name-servers might use the host name in order to decide which channels they should present to the client. The host name sent to the server usually is the unqualified host-name (without a domain part).
If not specified explicitly, the host name is determined
automatically.
Unfortunately, the Java platform specifies no standardized way for
reliably determining the host name.
For this reason, a multi-step process is used.
First, the library tries to call the hostname
command and uses its output.
If this command is not available or returns with an error, a
platform-specific environment variable (HOSTNAME on
UNIX-like systems, COMPUTERNAME on Windows systems)
is used.
If this environment variable is not set either, the library tries to
determine the hostname through DNS (by calling
InetAddress.getLocalHost().getHostName()).
If this fails as well, the library uses the string
“<unknown host>” as the host name.
Typically, this setting is chosen so that is has the same value as the corresponding setting in the client configuration.
The user name is sent to each TCP-based name-server when a connection is established. Some servers might use the user name in order to decide which process variables they should present to the client.
If not specified explicitly, the user name is determined
automatically.
Unfortunately, the Java platform specifies no standardized way for
reliably determining the user name.
For this reason, a multi-step process is used.
First, the library tries to use platform-dependent classes from the
com.sun.security.auth.module package.
If these classes are not available (they are not part of the Java
Standard Edition but are only bundled with certain Java run-time
environments) or their use results in an exception, the
user.name system property is used.
If this property is not set, the USERNAME environment
variable is used.
If this environment variable is not set either, the library uses the
empty string as the user name.
Typically, this setting is chosen so that is has the same value as the corresponding setting in the client configuration.
The default server port is used for two purposes. First, it is used as the target port for search requests when a configured target address does not specify the target port number explicitly. In particular, this port is used when a target address is determined automatically (see the section called “Determine UDP addresses automatically”). Second, the default server port is used when a reply to a search message contains an invalid server port (a port number of 0 or above 65535).
If this option is not specified, the value of the
EPICS_CA_SERVER_PORT environment variable is used.
This is the same environment variable that is also used by the C
library.
If the environment variable is not set, the protocol’s default port
(5064) is used.
Recent versions of the Channel Access protocol support the resolution of channel names via TCP. The TCP-addresses option specifies the list of server addresses (combination of IP address and TCP port number) that are contacted for name resolution via TCP.
Please note that name resolution via TCP is only supported in fairly recent versions of the Channel Access protocol (since Channel Access version 4.12).
If this option is not specified, it is initialized from the value of
the EPICS_CA_NAME_SERVERS environment variable.
This is the same environment variable that is also used by the C
library.
The value of the environment variable is expected to be a
space-separated list of addresses in the form “N.N.N.N:M” or
“N.N.N.N”, where “N.N.N.N” is the name server’s IP address and
“M” is the optional TCP port number.
If the TCP port number is not specified, the default server port is
used.
If the environment variable is not set, an empty list is used.
This has the effect that name resolution via TCP is disabled.
In most environments, UDP is used for resolving channel names. The UDP-addresses option specified the list of server addresses (combination of IP address and UDP port number) that are contacted for name resolution via UDP. This list may be augmented by a list of automatically determined addresses (see the section called “Determine UDP addresses automatically”).
If this option is not specified, it is initialized from the value of
the EPICS_CA_ADDR_LIST environment variable.
This is the same environment variable that is also used by the C
library.
The value of the environment variable is expected to be a
space-separated list of addresses in the form “N.N.N.N:M” or
“N.N.N.N”, where “N.N.N.N” is the name server’s IP address and
“M” is the optional UDP port number.
If the UDP port number is not specified, the default server port is
used.
If the environment variable is not set, an empty list is used.
However, automatically determined addresses might still be used.
If automatic address detection is also disabled, this effectively
disables name resolution via UDP.
If UDP addresses are set to be determined automatically, the channel-name resolver uses the broadcast addresses of all local interfaces as target addresses for name resolution. When sending messages to these broadcast addresses, the default server port is used. The channel-name resolver periodically checks the list of local interfaces, updating the list of broadcast addresses when new interfaces have been brought up or previously present interfaces have been shutdown.
Typically, there are only two reasons for disabling this option. When name resolution via UDP should be disabled completely in favor of name resolution via TCP, this option has to be disabled in order to avoid using automatically detected addresses. The other reason is when the computer running the client is connected to multiple networks and only servers on some of these networks shall be contacted. In this case, the broacast addresses of the networks that shall be used have to be set manually.
If this option is not specified, it is determined from the
EPICS_CA_AUTO_ADDR_LIST environment variable.
This is the same environment variable that is also used by the C
library.
If this environment variable is set to “NO” (not case-sensitive),
the automatic address detection is disabled. Otherwise, it is
enabled.
The maximum search period is the maximum amount of time (specified in seconds) that the name-resolver waits before sending a search request for a channel that could not be resolved again. With every failed resolution attempt, the channel-name resolver increases the time between two search requests in order to avoid overloading the network with search requests for channels that might never be found. However, it does not increase this time beyond the limit set by this option.
If this option is not specified, the value of the
EPICS_CA_MAX_SEARCH_PERIOD environment variable is
used.
This is the same environment variable that is also used by the C
library.
If the environment variable is not set, the default value of 60
seconds is used.
This is also the smallest value allowed for this option.
The echo interval is the time between sending two echo requests to
a TCP-based name-server.
Echo requests are sent in order to ensure that the connection is
still working.
If a beacon packet from the same server is received within this
interval, this is considered proof that the network connection is
okay and thus no echo request is sent.
For this reason, this setting should be chosen to be at least two
times as large as the max. interval between sending two beacons.
The beacon interval is configured on the server-side (typically by
setting the EPICS_CA_BEACON_PERIOD environment
variable).
Typically, this setting is chosen so that is has the same value as the corresponding setting in the client configuration. However, unlike that setting, this setting does not have any effect on the connection state of channels. The only reason why echo requests are also sent for a name-server connection is that actually sending some data might help the operating system to detect that a TCP connection has been interrupted, thus giving the name resolver a chance to establish a new connection.
If this option is not specified, the value of the
EPICS_CA_CONN_TMO environment variable is
used.
This is the same environment variable that is also used by the C
library.
If the environment variable is not set, the default value of 30
seconds is used.
The minimum interval that can be set is 0.1 seconds.
The multicast time-to-live (TTL) defines the number of hops a multicast packet might take before being delivered to its target. By default, the Channel Access protocol does not use multicast packets, but multicast packets might be sent if the list of UDP name-serves includes multicast addresses. In this case, this configuration option defines the TTL of these packets.
Due to limitations of the Java platform, the multicast TTL cannot be set when running on Java 6. The API needed for setting this option has been introduced with Java 7. When running on Java 6, this option is silently ignored. Even when running on Java 7 or newer, some platforms might not implement this option. In this case, the error handler is notified about the problem, but the name resolver continues operation without this option being set on the UDP socket.
If this option is not specified, the value of the
EPICS_CA_MCAST_TTL environment variable is
used.
This is the same environment variable that is also used by the C
library (starting with EPICS Base 3.16.1).
If the environment variable is not set, the default value of 1
is used.
The minimum value for this option is 1 and the maximum value is
255.
The error handler is used by the channel-name resolver to log errors that occur during its operation. For details, please refer to Section 4, “Error handling”.
The EPICS Jackie Client is designed to handle errors right where they
occur.
For example, when a read operation fails, the corresponding future
throws an exception.
If a monitor subscription cannot be created, the corresponding monitor
listeners are notified.
However, there are certain situations in which an error cannot be
associated with a certain context in which the corresponding exception
could be thrown.
For example, a server might send an error message which is not related
to a specific request or a malformed packet might be received on the
network port used for name resolution.
In these cases, the obvious solution is to write the error to a log and
continue operation.
However, EPICS Jackie tries to avoid a dependency on a specific logging
framework.
For this reasons, there is the concept of an error handler, that can be
specified when creating the configuration objects (
ChannelAccessClientConfiguration,
BeaconDetectorConfiguration, and
ChannelNameResolverConfiguration).
This error handler is called whenever an exceptional situation that
cannot be associated with a specific context is encountered.
Error handlers must implement the
ErrorHandler interface.
This interface has a single method handleError
that is called whenever an otherwise unhandled error is encountered.
With each call of this method, the context (in the form of the class in
which the error was encountered) is passed.
Typically, there also is an exception and sometimes even an error
message that is passed to this method, but these two parameters are
optional and might be null.
The EPICS Jackie library provides two default implementations of the
ErrorHandler interface.
JavaUtilLoggingErrorHandler uses the
java.util.logging framework for logging the error.
If an exception is passed, the error is logged as a warning, otherwise
it is logged as an informational message.
The NullErrorHandler simply does nothing.
This error handler can be used when errors shall not be logged at all.
If no error handler is specified explicitly, the configuration objects
are initialized with a
JavaUtilLoggingErrorHandler. When the
BeaconDetectorConfiguration and the
ChannelNameResolverConfiguration are created
automatically by the surrounding
ChannelAccessClientConfiguration they use the
same error handler that is also used by the
ChannelAccessClientConfiguration. Otherwise,
they use the JavaUtilLoggingErrorHandler by
default, even if the
ChannelAccessClientConfiguration is set to use a
different error handler.
An application will typically supply an error handler that delegates to
the logging framework used by the application (for example Apache
Commons Logging or SLF4J).
If the application uses java.util.logging as its
logging framework or java.util.logging is configured
to redirect to the application’s logging framework, the
JavaUtilLoggingErrorHandler can be used as-is, of
course.
The listener lock-policy allows a developer to configure how the library deals with locks when removing listeners or destroying channels or monitors. This behavior is configurable because there is a trade-off between having strong consistency guarantees and avoiding deadlocks.
Such a deadlock can occur when a listener acquires a lock that is also acquired by code removing that listener or destroying the object to which the listener is registered (in the case of channels and monitors). This risk of a deadlock stems from the fact that the code calling the listener also acquires an internal lock and holds it while calling the listener. This lock is needed because it is the only way to assure that a listener is not called after the remove or destroy method has returned.
By default, the BLOCK policy is used, which
guarantees that a listener is never called after the method removing it
or the destroy method has returned.
However, this policy has the disadvantage that a deadlock can occur
when the listener acquires a lock that is also acquired by code
removing the listener or destroying the object to which the listener is
registered.
A different behavior is seen when choosing the
IGNORE or REPORT policy.
In this case, even removing a listener (or destroying the respective
object) while holding a lock that is also acquired by the same listener
(or any listener registered with the object in case of the destroy
method) cannot cause a deadlock.
The price one has to pay for this is that it is no longer guaranteed
that the listener is not going to be notified after the method removing
the listener or the destroy method has returned.
The difference between the IGNORE and the
REPORT policy is that the
REPORT policy causes the method that removes the
listener or the destroy method to throw a
ConcurrentNotificationException
when it detects that the listener might receive one more notification.
In either case, the listener will receive at most one more notification
after that method returns, but if the policy is set to
REPORT and the method does not throw an exception,
it is guaranteed that the listener is not going to be
called again – just like when using the BLOCK
policy.
Even when using the IGNORE or
REPORT policy, having listeners that might
potentially block is not without danger.
By default, listeners are executed in the I/O thread and thus a
listener that blocks will result in the I/O thread being blocked.
Please refer to Section 6, “Threading strategy” for
details.
The concept of how threads used by the
DefaultChannelAccessClient are managed is
separated into the
ClientThreadingStrategy.
The default implementation of this interface,
DefaultClientThreadingStrategy, should be
suitable for most use cases.
However, applications wanting to use a different threading model can
easily provide their own implementation of the
ClientThreadingStrategy interface.
The DefaultClientThreadingStrategy is the
default implementation used by the
DefaultChannelAccessClient if no other
threading-strategy is specified.
This threading strategy creates one thread that handles beacon
detection and name resolution and one additional thread for each
connection with a channel server.
Channels that are hosted by the same server share a connection, so
that the number of server connections is usually rather small.
By default, this threading strategy notifies listeners (like channel connection listeners, future completion listeners, and monitor event listeners) in the same thread that triggers the event. This implementation is very efficient and safe as long as the listeners do not block or need a considerable amount of processing time.
When being constructed explicitly (in contrast to being created
implicitly by the DefaultChannelAccessClient),
the DefaultClientThreadingStrategy allows for
changing this behavior.
The user can specify an
ExecutorService that is used for
calling listener methods.
When this option is used, blocking listeners do not pose a threat to
the stability of the client, provided that the
ExecutorService’s
execute method does not block.
Even if such a configuration is used, blocking listeners are still not desirable because they might cause the execution of other listeners to be delayed if a fixed-size thread-pool is used and all threads are occupied by blocking listeners. In addition to that, delegating the execution of listeners to an executor service causes significant overhead for coordination in order to ensure that event notifications are being delivered in the correct order. Last but not least, such a configuration cannot guarantee that a listener will not be called after it has been removed. If events have been queued before the listener is removed, the listener is still going to be called for those events.
For these reasons, the default option of notifying listeners in the calling thread should be preferred. The option of using an executor service should only be considered when implementing all listeners in a way so that they do not block is not feasible.
For some applications, the threading model provided by the
DefaultClientThreadingStrategy might not be
convenient.
For example, there might be applications that connect to a large
number of servers, but want to keep the number of threads to a
minimum.
Such an application could easily provide its own implementation of the
ClientThreadingStrategy interface that only
creates a single thread that takes care of handling all I/O
operations, including the beacon detector, the channel-name resolver
and all channel-server connections.
Creating such a threading strategy is as simple as creating a
SimpleCommunicationController that is
repeatedly called from the processing thread.
The threading strategy can then simply pass this communication
controller to all the
CommunicationProcessors used for the
beacon detector, the channel-name resolver, and the channel-server
connections.
Another threading strategy might want to use a pool of threads for
processing the various communication controllers.
Such an implementation can also be built based on the
SimpleCommunicationController.
However, as soon as more than one thread is involved, care must be
taken that a single communication processor is not processed by more
than one thread because communication processors are not thread-safe.
The DefaultChannelAccessClient, which is the
default implementation of the
ChannelAccessClient interface provided
by the EPICS Jackie library, already has plenty of customization
options.
First of all, many options can be changed by providing a modified
configuration as described in Section 3, “Configuration options”.
The handling of errors can be customized through the use of error
handlers like described in Section 4, “Error handling”.
If the default threading model used by EPICS Jackie is not suitable for
an application, it can provide its own threading strategy as described
in Section 6, “Threading strategy”.
If all these customization options are not sufficient for a specific
application, it can customize things even further by providing its own
implementation of ChannelAccessClient,
ChannelAccessChannel, and
ChannelAccessMonitor.
All these types are interfaces in order to allow for easy adaption.
Such a custom implementation does not have to implement all features
from scratch.
The implementation of a channel can be derived from
AbstractChannelAccessChannel, which already
implements most of the methods specified by the interface.
The implementation of a monitor can be derived from
AbstractChannelAccessMonitor, which implements
the whole management of monitor listeners.
The ChannelAccessClient interface is
very simple, so there is no abstract base class implementing it.
However, the implementation of a client does not have to be written from
scratch either:
Beacon detection can be delegated to
DefaultBeaconDetector, the default implementation
of the BeaconDetector interface.
Resolving channel names can be handled by
DefaultChannelNameResolver, the default
implementation of the ChannelNameResolver
interface.
The ChannelAccessServerConnection class can be
used as a base for implementing the communication with Channel Access
servers.
This base class takes care of establishing the connection (including
version negotiation) and encoding and decoding messages.
Finally, the components that are part of the EPICS Jackie Common module provide building blocks that can be used when creating a client implementation and might even be useful for applications beyond the scope of a client. Please refer to Chapter IV, EPICS Jackie Common Components to learn more about the components provided by that module.
The EPICS Jackie Common Components module assembles various components that are useful when building software dealing with the Channel Access protocol. These components are not limited to a certain application (for example a client), but can be used to build any kind of software for handling Channel Access, including applications like servers, gateways, or protocol analyzers.
These components can be coarsely separated into four categories: Components dealing with the Channel Access protocol (described in Section 1, “Channel Access message codec”), components dealing with Channel Access values (described in Section 2, “Channel Access value objects”), components for handling asynchronous network I/O (described in Section 3, “I/O support”), and general utilities.
This document does not give a complete description of all the components provided by the library, but is rather intended as an overview and starting point. For a complete description of all components, including detailed API specifications, please refer to the API reference documentation.
The primary class for dealing with the Channel Access protocol on a
per-message basis is the
ChannelAccessMessageCodec.
This class provides methods for serializing and deserializing the
messages supported by the Channel Access protocol.
In its deserialized form, each message is represented by an instance of
one of the classes derived from
ChannelAccessMessage.
For the serialized form, the
ChannelAccessMessageCodec uses instances of
ByteSink (for serialization) and
ByteSource (for deserialization) from the
I/O support components.
The ChannelAccessMessageCodec provides
serialization and deserialization support for all message types and all
parties involved in communication (client, server, repeater, TCP, UDP,
etc.). Therefore, it should be sufficient for handling the Channel
Access protocol in all situations. Internally, the
ChannelAccessMessageCodec makes use of the
ChannelAccessValueCodec (see
Section 2, “Channel Access value objects”) for serializing and deserializing
Channel Access values.
The Channel Access protocol has a type system that includes 39 different data-types. Of these data types, thirty can only be used in read operations, two can only be used in write operations, and seven can be used in both read and write operations.
The EPICS Jackie library uses interfaces for representing the various
data-types.
However, application code should never create implementations of these
interfaces.
Only the implementations provided by the library (and exposed through
ChannelAccessValueCodec and
ChannelAccessValueFactory) must be used.
The only reason for using interfaces instead of classes is the complex
type-hierarchy of the Channel Access type system that cannot be
represented adequately without using multiple inheritance.
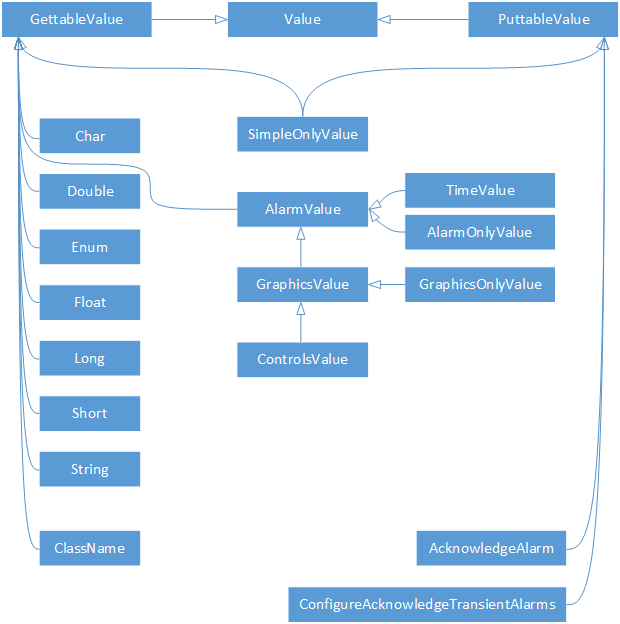
Figure IV.1, “Overview of the ChannelAccessValue class hierarchy” shows the basic outline
of the type hierarchy used for the Channel Access value objects.
The “ChannelAccess” prefix has been stripped from all class names for
brevity.
All types inherit from
ChannelAccessValue, the types that can be
used in read operations inherit from
ChannelAccessGettableValue, and the types
that can be used in write operations inherit from
ChannelAccessPuttableValue.
Even though it cannot be seen from this figure, the
ChannelAccessClassName,
ChannelAccessAcknowledgeAlarm, and
ChannelAccessConfigureAcknowledgeTransientAlarms
types are special because there are no sub-interfaces derived from them.
They directly represent values of the types
DBR_CLASS_NAME, DBR_PUT_ACKS, and
DBR_PUT_ACKT.
The seven types in the left column of the figure (char, double, enum,
float, long, short, string) actually are base-interfaces that are
shared by all types having the respective element type.
For example, all types that contain elements of type double inherit from
ChannelAccessDouble.
The four types in the center column and the three types in the right
column are the base interfaces shared by all types that have certain
properties in common (but may have different element types).
The types in the right column differ from the types in the center column
in the fact that the types in the right column only
have their specific properties, while the ones in the center column
might have additional properties that are just not visible in the base
interface.
For example, an instance of
ChannelAccessAlarmValue might actually
also implement
ChannelAccessGraphicsValue, while a
ChannelAccessAlarmOnlyValue is guaranteed
to be neither a ChannelAccessTimeValue,
nor a ChannelAccessGraphicsValue, nor a
ChannelAccessControlsValue.
Consequently, there are interfaces that mix the interfaces from the left column with the interfaces from the center and right columns.
Figure IV.2, “Class hierarchy of the ChannelAccessDouble type” shows this sub-hierarchy,
using the ChannelAccessDouble type as an
example.
Again, the “ChannelAccess” prefix has been stripped from all class names
for brevity.
There are seven interfaces that inherit from
ChannelAccessDouble.
At the same time, each of these interfaces inherits from one of the
base-types that do not depend on the element type.
For numeric element types (char, double, float, long, short), the complete picture is even a bit more complex:
As shown in Figure IV.3, “Class hierarchy of numeric ChannelAccessValue types”, there are
specialized versions of the
ChannelAccessGraphicsValue and
ChannelAccessControlsValue for numeric
element types and even more specialized versions for floating-point
element types.
The reason for this is that the graphics and controls types for numeric
types share a certain common structure of their properties.
For each of the 39 types known by the Channel Access protocol, there is one interface corresponding to this type as listed in Table IV.1, “Channel Access value types and corresponding interfaces”.
| Channel Access value type | Java interface |
|---|---|
| DBR_STRING |
ChannelAccessSimpleOnlyString
|
| DBR_SHORT |
ChannelAccessSimpleOnlyShort
|
| DBR_FLOAT |
ChannelAccessSimpleOnlyFloat
|
| DBR_ENUM |
ChannelAccessSimpleOnlyEnum
|
| DBR_CHAR |
ChannelAccessSimpleOnlyChar
|
| DBR_LONG |
ChannelAccessSimpleOnlyLong
|
| DBR_DOUBLE |
ChannelAccessSimpleOnlyDouble
|
| DBR_STS_STRING |
ChannelAccessAlarmOnlyString
|
| DBR_STS_SHORT |
ChannelAccessAlarmOnlyShort
|
| DBR_STS_FLOAT |
ChannelAccessAlarmOnlyFloat
|
| DBR_STS_ENUM |
ChannelAccessAlarmOnlyEnum
|
| DBR_STS_CHAR |
ChannelAccessAlarmOnlyChar
|
| DBR_STS_LONG |
ChannelAccessAlarmOnlyLong
|
| DBR_STS_DOUBLE |
ChannelAccessAlarmOnlyDouble
|
| DBR_TIME_STRING |
ChannelAccessTimeString
|
| DBR_TIME_SHORT |
ChannelAccessTimeShort
|
| DBR_TIME_FLOAT |
ChannelAccessTimeFloat
|
| DBR_TIME_ENUM |
ChannelAccessTimeEnum
|
| DBR_TIME_CHAR |
ChannelAccessTimeChar
|
| DBR_TIME_LONG |
ChannelAccessTimeLong
|
| DBR_TIME_DOUBLE |
ChannelAccessTimeDouble
|
| DBR_GR_STRING |
ChannelAccessAlarmOnlyString
|
| DBR_GR_SHORT |
ChannelAccessGraphicsOnlyShort
|
| DBR_GR_FLOAT |
ChannelAccessGraphicsOnlyFloat
|
| DBR_GR_ENUM |
ChannelAccessGraphicsEnum
|
| DBR_GR_CHAR |
ChannelAccessGraphicsOnlyChar
|
| DBR_GR_LONG |
ChannelAccessGraphicsOnlyLong
|
| DBR_GR_DOUBLE |
ChannelAccessGraphicsOnlyDouble
|
| DBR_CTRL_STRING |
ChannelAccessAlarmOnlyString
|
| DBR_CTRL_SHORT |
ChannelAccessControlsShort
|
| DBR_CTRL_FLOAT |
ChannelAccessControlsFloat
|
| DBR_CTRL_ENUM |
ChannelAccessGraphicsEnum
|
| DBR_CTRL_CHAR |
ChannelAccessControlsChar
|
| DBR_CTRL_LONG |
ChannelAccessControlsLong
|
| DBR_CTRL_DOUBLE |
ChannelAccessControlsDouble
|
| DBR_PUT_ACKT |
ChannelAccessConfigureAcknowledgeTransientAlarms
|
| DBR_PUT_ACKS |
ChannelAccessAcknowledgeAlarm
|
| DBR_STSACK_STRING |
ChannelAccessAlarmAcknowledgementStatus
|
| DBR_CLASS_NAME |
ChannelAccessClassName
|
The ChannelAccessAlarmOnlyString and
ChannelAccessGraphicsEnum interfaces are
special because they are used for more than one Channel Access value
type.
The reason is that the DBR_STS_STRING,
DBR_GR_STRING, and DBR_CTRL_STRING
types are completely identical, as are the
DBR_GR_ENUM and DBR_CTRL_ENUM
types.
For reasons explained earlier, the whole type hierarchy of the Channel
Access value types relies on interfaces instead of classes.
Unfortunately, the implementations of interfaces cannot be limited to a
certain package. Unlike a class, an interface does not have a
constructor that could be made package-private.
Still, it is very important that an application does
not create its own implementations of the
interfaces.
Many parts of the code involving Channel Access values, in particular
code serializing the values, rely on the fact that the values implement
the correct interfaces (and not more interfaces).
This is particularly important for marker interfaces like
ChannelAccessGettableValue and
ChannelAccessPuttableValue.
The ChannelAccessValueFactory is the class
through which objects implementing the interfaces of the type hierarchy
can be created safely.
The objects created this way are accepted by
ChannelAccessValueCodec and can be serialized
correctly.
The ChannelAccessValueCodec is the class
responsible for serialization and deserialization of Channel Access
values to ByteSinks and from
ByteSources.
The objects created by the deserialization methods of this class
implement the type-hierarchy correctly (actually, they are the same
implementations that are also used by
ChannelAccessValueFactory) and can also be
serialized again.
The EPICS Jackie library includes a small but powerful framework for creating asynchronous I/O services. This framework is the internal basis for all the network-communication code of the EPICS Jackie Client.
The components provided by this I/O framework can roughly be split into two categories: There are utilities that allow dealing with a (theoratically endless) stream of bytes (described in Section 3.1, “Byte streams”) and there are utilities dealing wih the handling of asynchronous I/O channels (described in Section 3.2, “Asynchronous I/O”).
There are two types of byte streams:
A ByteSource acts as an input stream,
providing data that has been read from some source (typically a
network socket).
Correspondingly, a ByteSink acts as an
output stream, accepting data and writing it to some kind of sink
(typically, this also is a network socket).
The interface of ByteSource and
ByteSink resembles the interface of
Java’s ByteBuffer class.
The most notable difference is that there are no read and write
methods taking an offset.
The read methods always consume the bytes right at the beginning of
the data remaining in the the source.
In the same way, the write methods always append the bytes right at
the end of the data already written to the sink.
Sometimes, a read or write operation only makes sense if a whole
data-set can be read or written.
The ByteSource and
ByteSink provide atomic read and write
operations for this purpose:
When an atomic read operation fails, the source is rolled back to the
state it was in before the atomic read operation started, so that the
data consumed by the read operation is still available for the next
read operation.
In the same way, when an atomic write operation fails, the sink is
rolled back to the state it was in before the atomic write operation
started, so that none of the data written by the write operation is
actually written.
Internally, this works by using buffers that store the data.
This feature is very useful when processing a protocol that relies on some form of packets or messages. In this case, the code can fail if a message cannot be read or written completely, relieving it from the burden to keep track of which data has already been read or written and having to continue at the right point.
The ByteSource has a
remaining method that returns the number of
bytes that can be read from the byte source without a
BufferUnderflowException being thrown.
However, the value returned by this method only is a lower estimate,
meaning that there might actually be more data available.
Typical implementations will return the number of bytes available in
the internal buffer and throw a
BufferUnderflowException when reading
beyond the limit of this buffer, but some implementations might choose
copying additional bytes into the buffer when its end is reached, in
which case the estimate might be too small.
The ByteBufferByteSource and
ByteBufferByteSink are implementations that
internally use a list of ByteBuffers for
buffering data.
These implemantations are very convenient when used with asynchronous
I/O because they allow for an easy integration with Java’s
Channel API that also works with
ByteBuffers.
The ByteBufferByteSource implements
the remaining method so that the number of
bytes remaining in the buffers is returned (unless this number
exceeds Integer.MAX_VALUE in which case that
number is returned instead).
This means that an application reading from the byte source can check
whether the data remaining in the byte source is sufficient for
finishing an atomic read operation and can fail early with a
BufferUnderflowException if the
remaining bytes are not sufficient.
The AbstractSocketChannelConnection class
described in Section 3.2, “Asynchronous I/O” provides a convenient
way of connecting a SocketChannel with
the ByteSource and
ByteSink APIs.
In Java, asynchronous I/O is typically performed through the
facilities of the Java NIO framework.
This means that a Selector has to be created
and Channels have to be registered
with this selector in order to be notified when the operating system
is ready for an I/O operation.
Managing the selector and its associated channels can be tedious because it means that the component responsible for a certain channel has to be identified and notified. In addition to that, components often want to perform certain operations in certain time intervals, independent of the I/O state of their channel. In this case, the select operation on the selector has to be limited in time so that the timed operation can be run at the right point in time.
The asynchronous I/O framework of EPICS Jackie provides a component
that takes care of all these details.
This component is called the
CommunicationController.
The communication controller allows for both kind of notifications:
being notified, when a channel is ready for an I/O operation and
being notified when a timer has expired.
The registerChannel method is used to
register a ChannelProcessor that is
notified when the corresponding Channel
is ready for I/O.
The return value of this method is a
SelectionKey that can be used by the channel
processor in order to configure when it wants to be notified.
Most processors will want to always be notified when the channel is
ready for a read operation (because new data has arrived), but will
only be interested to be notified when the channel is ready for a
write operation when they actually have data in their write buffer.
The registerTimer method is used to
register a TimerProcessor that is
notified after a certain time interval has passed.
It is assumed that a communication controller only uses a single thread so that channel and timer processors can be designed without having to worry about thread safety. As one component might register more than one channel or timer processor, a communication controller has to guarantee that this holds true, even for different processors that are registered with the same controller.
The SimpleCommunicationController is an
implementation that deals with all the tasks of a communication
controller, doing its work in a single method,
processTimersAndIO, that has to be called
repeatedly by an application thread.
The CommunicationProcessor interface
is a simple interface that can be implemented by a component in order
to get the CommunicationController
injected.
This way, a component using a communication controller can be designed
without having any dependencies on how the communication controller
(and its associated thread) is created or which implementation is
used.
The AbstractSocketChannelConnection is a good
starting point for writing a component that uses a
SocketChannel for asynchronous I/O.
Its constructor takes a socket channel and a communication controller
and takes care of registering the channel with the communication
controller.
Internally, it uses instances of
ByteBufferByteSource and
ByteBufferByteSink that are connected with the
channel so that data that arrives on the channel is made available in
the byte source and data that is written to the byte sink is written
to the channel.
The application code typically only has to implement (some of) the
five event handler methods (onConnect,
onDestroy,
onReceive,
onReceiveFinished,
onSend) and can simply use the provided byte
source and byte sink to read and write data from within these methods.