- I.1. Cassandra PV Archiver architecture
- I.2. Division of samples into sample buckets
- I.3. Mapping of raw samples to decimated samples
- I.4. Sample generation for cascaded decimation levels
- III.1. Administrative UI navigation bar (full screen size)
- III.2. Administrative UI navigation bar (small screens)
- III.3. Changing the password
- III.4. Add channel view
- IV.1. CSS Data Browser options in the preferences tree
- IV.2. CSS Data Browser archive data server URLs
- IV.3. CSS Data Browser default archive data sources
- IV.4. CSS Data Browser perspective
The Cassandra PV Archiver is a scalable archiving solution for storing time-series data inside an Apache Cassandra database. While the Cassandra PV Archiver has been designed to archive the values of process variables in industrial automation scenarios, it is not limited to this specific application. In fact, it is suitable to archive any kind of data that can be represented as a time-series and new data sources can easily be added through extensions (see Chapter V, Extending Cassandra PV Archiver). The default distribution is bundled with a modules that allows for easy archiving of process variables that can be accessed over the Channel Access protocol, which is typically used in EPICS-based control systems.
This document is intended as a reference guide for administrators that want to deploy the Cassandra PV Archiver, developers that want to extend it, and user that want to manage the archiver’s configuration or to access archived data.
This chapter should be of interest to all audiences. In addition to that, administrators are most likely going to be interested in Chapter II, What’s new in Cassandra PV Archiver 3.x and Chapter III, Cassandra PV Archiver server. Developers are most likely going to be interested in Chapter V, Extending Cassandra PV Archiver. Users are most likely going to be interested in Chapter IV, Cassandra PV Archiver clients.
In addition to reading this document, administrators and developers who are not familiar with Apache Cassandra databases are encouraged to read the Cassandra documentation provided by DataStax.
The Cassandra PV Archiver acts as a bridge between an Apache Cassandra database and control-system applications. It takes care of monitoring process variables for changes and persisting them in the database. At the same time, it provides an interface for querying the data stored in the database in a convenient way, without having to deal with low-level details like the exact storage layout. The architecture of the Cassandra PV Archiver is depicted in Figure I.1, “Cassandra PV Archiver architecture”.
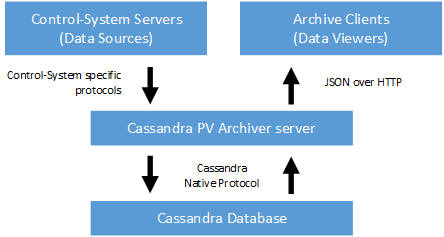
The control-system servers provide process variables that are monitored by the Cassandra PV Archiver server. The Cassandra PV Archiver can support arbitrary control-systems through so-called control-system supports. The Cassandra PV Archiver server is bundled with a control-system support for the Channel Access protocol (see Appendix D, Channel Access control-system support), but it can easily be extended with other control-system supports (see Chapter V, Extending Cassandra PV Archiver). The protocol used for communication between the control-system entirely depends on the control-system support, so that the control-system’s native protocol can be used for optimal performance.
The Cassandra PV Archiver server takes care of managing archived process variables (which are called “channels” in the terminology of the Cassandra PV Archiver). This includes managing configuration and meta-data as well as storing the archived samples in the Cassandra database. However, the actual storage format of individual samples is defined by each control-system support. This allows each control-system support to choose a storage format that is optimized for the structure of samples as they are supplied by the underlying control-system framework.
The Cassandra PV Archiver server uses Cassandra’s native protocol for writing data to and reading data from the Apache Cassandra database. Even though the Cassandra PV Archiver and the Cassandra database are depicted as monolithic blocks in Figure I.1, “Cassandra PV Archiver architecture”, each of these blocks can actually consist of many sever instances that form a cluster. The Cassandra PV Archiver server instances and the Apache Cassandra database servers can be deployed on separate clusters, but in a typical setup they will actually be colocated on the same servers.
For accessing archived samples, a user uses an archive client (see Chapter IV, Cassandra PV Archiver clients). This archive client accesses the Cassandra PV Archiver server through a JSON-based web-service protocol. Each server instance can provide access to the complete archive, so a client can use a round-robin strategy when choosing the server that is contacted in order to retrieve data. As an alternative to that, special server instances that are dedicated to providing read access to the archive might be deployed.
In order to offer good read and write performance, the Cassandra PV Archiver arranges the data in a way that is optimized for the Cassandra database. Cassandra tables organize rows in so-called partitions. A partition is a set of rows that is stored on the same node. While the rows within a partition have an order (and thus range queries are possible), there is no order between partitions.
When storing time-series data, this means that only data in the same partition can easily be queried for a certain period of time. Unfortunately, storing all data for a certain channel in a single partition is typically not an option because the size of a partition should typically not exceed 100 MB in order to attain a good performance .
The Cassandra PV Archiver solves this issue by dividing the data stored for each channel into so-called sample buckets (see Figure I.2, “Division of samples into sample buckets”). Each sample bucket stores the data for a certain period of time. When a sample buckets hits a size of about 100 MB, a new sample bucket is started. The information about how periods of time map to sample buckets is stored in a separate table. When reading data, the Cassandra PV Archiver first finds out which sample buckets exist for the specified period of time and then retrieves the actual data from these sample buckets.
![[Note]](docbook/images/note.png) | Note |
|---|---|
By default, Apache Cassandra compresses data before writing it to disk. For this reason, the on-disk size of a sample bucket is typically significantly less than 100 MB. However, the 100 MB limit recommended for partitions applies to the uncompressed size. |

Typically, an administrator or developer does not have to deal with these details of how data is stored. However, it is important to understand these details when optimizing the configuration of the Cassandra database cluster for performance and when reading data directly from the database, bypassing the query interface provided by the Cassandra PV Archiver.
Each control-system support uses a separate table (or possibly even a set of tables) for storing its samples. However, the control-system support does not have to deal with managing sample buckets. When writing a sample, the Cassandra PV Archiver tells the control-system support to which sample bucket a sample belongs. This way, the control-system support can simply store the sample in this sample bucket. In the same way, when reading data, the Cassandra PV Archiver only asks the control-system support for data from a single sample bucket, so that the control-system support can use simple range queries.
Users often want to retrieve samples for an extended period of time, for example in order to get a trend of how a process variable changed over months or even years. In this case, retrieving the raw samples as they were logged is rather inefficient. For example, if a process variable is logged at an update rate of one sample per second, there are 86,400 samples per day or 31,536,000 samples per year. When plotting the trend of a process variable’s value for a whole year, using 31 million samples does not make sense because the effective resolution of the plot will limit the amount of details that can be seen to a much coarser level. More importantly, retrieving the data for 31 million samples can take a considerable amount of time and typically a user will not want to wait for a long time if she is just interested in getting a quick overview.
For this reason, the Cassandra PV archiver supports so-called decimated samples. These decimated samples are generated asynchronously in the background while data is being archived. When retrieving data from the archive, this decimated data can be used when lower resolution data is sufficient for satisfying the user’s request. Decimated samples are organized in so-called decimation levels. Each decimation level for a certain channel stores samples at a fixed rate.
Typcially, the density of these decimation levels is chosen so that the distance between two samples increases exponentially with each decimation level. For example, when having a process variable with a native update rate of approximately one sample per second, the administrator might add decimation levels with decimation periods of 30 seconds, 15 minutes, and 6 hours. When plotting data for a whole year, one might then select the data from the decimation level with a decimation period of 6 hours, resulting in only 1,460 samples being returned instead of approximately 31 million raw samples.
The samples that are generated for decimation levels are always generated with a fixed distance specified by the decimation period of that decimation level. The details of how a decimated sample is generated are left to each control-system support. For example, a simple algorithm might choose to simply use one raw sample for each decimated sample, resulting in a “decimation” process in the literal sense. A more advanced algorithm, on the other hand, might choose to apply statistical operations on the source samples for the relevant period of time, calculating a mean and other stastical properties.
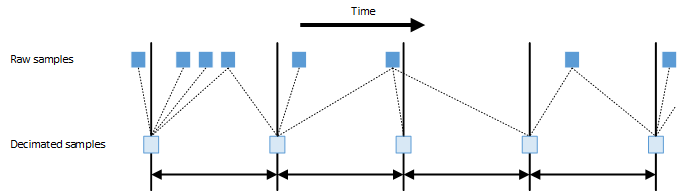
Figure I.3, “Mapping of raw samples to decimated samples” shows how decimated samples are generated from raw samples. For each decimated sample, the Cassandra PV Archiver passes one raw sample before or at the same time as the decimated sample to be generated and all raw samples after the decimated sample but before the next decimated sample to be generated. This way, the control-system support has all relevant information for the whole period for which the decimated sample is generated. This means that a decimated sample represents the period after its time stamp. For example, when having a decimation level with a decimation period of 30 seconds, the decimated sample with a time stamp of 14:12:30 will represent the interval [14:12:30, 14:13:00).
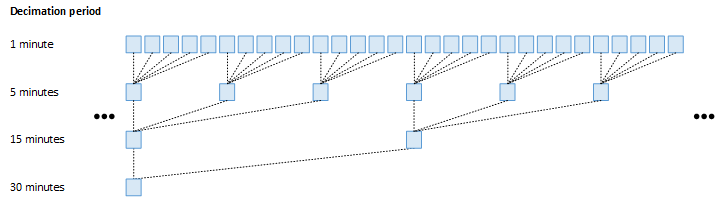
When there are multiple decimation levels for a channel, the decimated samples for longer decimation period are generated from decimated samples from shorter decimation periods (if the longer period is an integer multiple of the shorter period). This way, the amount of data that has to be processed is reduced dramatically (see Figure I.4, “Sample generation for cascaded decimation levels”).
One of the key goals that were in mind when designing the Cassandra PV Archiver was scalability. The Cassandra PV Archiver is designed to work both for very small setups (possibly as small as a single node installation) and very large scale setups (with tens or even hundreds of nodes). By using Apache Cassandra as the data store, the Cassandra PV Archiver can scale linearly, increasing the number of channels that can be handled and the amount of data that can be stored with each node added.
The Cassandra PV Archiver is not just scalable when making the first deployment. In fact, an existing deployment can easily be scaled up by adding more nodes with zero downtime as the demand grows. However, there are a few limitations regarding the data that can be stored for individual channels, of which the administrator should be aware. These limitations are largely instrinsic to the use of Apache Cassandra as the data store, but for some of them there exist workarounds that are described in the next paragraphs.
The archiving of each sample results in an INSERT
statement being executed in the Cassandra database.
As the number of statements that can be executed per second is usually
limited to something in the order of 100,000 statements per second per
node, archiving samples at extremely high rates is typically not a
good idea.
For example, when having channels with an update rate of about 1 kHz,
only about one hundred channels could be archived per node.
In additition to that, samples for the same channel are archived one
after another.
This means that the next sample is only archived once the
INSERT statement for the precding sample has
finished.
Due to the latency involved in executing each statement, this
effectively limits the rate at which samples for a single channel can
be written.
The workaround for this issue can be implemented by providing a custom
control-system support (see Chapter V, Extending Cassandra PV Archiver) that archives
samples at a lower rate.
For example, a control-system support can choose to accumulate all
samples that are received within a second and then create and archive
a “meta-sample” that actually contains the data of all these samples.
This reduces the number of INSERT statements
required and can thus reduce the load significantly.
As a side effect, this also resolves the latency problem.
For most scenarios, it should not be necessary to implement this workaround: The Cassandra PV Archiver typically works fine at update rates of about 10 Hz and supervisory control and data acquisition (SCADA) systems rarely deal with significantly higher data rates. Therefore, implementing this workaround only has to be considered when archiving data from a system with exceptionally high update rates.
As described in Section 2, “Data storage”, archived samples are organized in sample buckets. In order to ensure data consistency even in the event of a server crash at a very incovenient point in time, the Cassandra PV Archiver takes special precautions when creating a new sample bucket. These precautions result in a significant overhead when creating a new sample bucket, so that creating a new sample bucket very frequently is not advisable. This means that a channel producing data at a rate of tens of megabytes per second should not be (directly) archived with the Cassandra PV Archiver.
More importantly, the meta-data about which sample buckets exist is
stored in a single partition.
When deleting old samples, the corresponding reference to the sample
bucket is removed by issuing a DELETE statement
in the database.
In Apache Cassandra, a DELETE statement results in
a so-called tombstone being written.
When a lot of tombstones accumulate, this can have a significant
impact on read operations, which is why Apache Cassandra aborts a read
opertion when it encounters too many tombstones (please refer to the
Cassandra documentation
for details).
Typically, this is not a problem, but when inserting large amounts of data at comparedly high rates and only retaining this data for a limited amount of time, the number of tombstones generated when deleting old data might actually exceed this limit.
There are two possible workarounds. The first one is changing the
configuration options for Apache Cassandra. By reducing the so-called
GC grace period, tombstones can be discarded earlier so that the
number of tombstones that is accumulated can be reduced.
Please be sure to understand the consequences of this change before
applying it.
It is very important that the periodic
nodetool repair operation runs more frequently than
the GC grace period.
If not, deleted data can reappear, which in the context of the
Cassandra PV Archiver can result in data corruption.
The other change is increasing the number of tombstones that may be
encountered before aborting a read operation.
Increasing this number has an impact on the memory consumption of read
operations and read operations that encounter many tombstones may run
very slowly.
The second and preferred workaround is to store large amounts of data outside the Apache Cassandra database, for example using a scalable, distributed file-system (like Ceph). Such a solution can be implemented by providing a custom control-system support that stores the raw data in files and archives the meta-data (which file contains the data for a specific sample) using the Cassandra PV Archiver.
As a rule of thumb, you should consider storing the sample data outside the Cassandra database when the average data rate of a single channel exceeds the order of 50 KB per second. The average data rate means the rate averaged over an extended amount of time. For example, having a burst of data at a rate of 5 MB per second for ten seconds is fine when it is typically followed by a period of 30 minutes where virtually no data is archived.
The Cassandra PV Archiver 3.0 is intended as a replacement for the Cassandra Archiver for CSS 2.x. While sharing some of the concepts with the Cassandra Archiver for CSS 2.x, the code for the Cassandra PV Archiver 3.0 has actually been rewritten from scratch. The Cassandra PV Archiver 3.0 uses a new, CQL-based storage architecture that provides a significant improvement in performance and also simplifies the structure of the stored data, enabling direct data access for special applications. Unfortunately, this means that data archived with the Cassandra Archiver for CSS 2.x is not compatiable with the Cassandra PV Archiver 3.0 and has to be converted manually.
In addition to the change of the data format, the Cassandra PV Archiver 3.0 brings many new features that make it more scalable and simplify the deployment and operation:
- Completely new web interface for monitoring and configuring the archive cluster.
- Changing the configuration of channels (including renaming channels and moving channels between servers) without having to shutdown archiving servers.
- Asynchronous sample writer, making the best use of multi-core CPUs.
- Web-service interface for accessing the archive, simplifying the deployment of clients.
As the list of changes is so vast, even users already familiar with the Cassandra Archiver for CSS 2.x are strongly encouraged to read the complete manual of the Cassandra PV Archiver 3.0.
Version 3.0.1 is a bugfix release that fixes three bugs in the archive-access JSON interface. The first bug caused an exception when trying to retrieve enum samples, making it impossible to retrieve such samples via the JSON interface. The second bug caused incorrect values to be sent when an enum sample had more than a single element. The third bug concerned the serialization of the special “disabled” and “disconnected” samples. Those samples where always presented with a quality of “original”, even if they actually were decimated samples and should thus have had a quality of “interpolated”.
All the bugs fixed in this release only concern the archive-access interface. This means that data written by previous releases has not been affected by the aforementioned bugs and is correctly serialized after installing this update.
Version 3.0.2 is a bugfix release that fixes an issue that could result in an extreme memory consumption when generating decimated samples. When the source samples that were used for generating decimated were very scarce (had a density that was much smaller than the density of the generated samples), this could lead to an extreme memory consumption, resulting in a denial of service. As a side-effect, the server process would not respond any longer because the thread generating the decimated samples would hold a mutex for an extended period of time. Typically, this issue would primarily occur when starting the server after it had been stopped for some time or when adding new decimation levels.
The bugfix limits the number of samples that are generated from a single source sample, interrupting the process when the limit is reached and waiting for the generated samples having been written to the database before continuing. This limits the memory consumption and also releases the mutex periodically so that threads waiting for the mutex do not block for an extended period of time.
The bug fixed in this release only concerns internal implementation details. This means that data written by previous releases is correct and does not have to be regenerated or updated.
Version 3.0.3 is a bugfix release that fixes four issues. Three of these issues affected the generation of decimated samples. The fourth issue was in a shared component and would cause an exception in certain situations with a very high system load.
The three bugs in the sample generation process could result in no more decimated samples being generated for a certain channel. This was caused by a problem that would result in already existing decimated samples being generated again when the decimation process was previously interrupted unexpectedly (e.g. due to a server restart). On its own, this bug would only have performance implications and not affect correct behavior. However, due to a second bug that was introduced in version 3.0.2, it would lead to the whole decimation process for the channel being brought to a halt. The third bug could have a negative impact on performance because the decimation process would not always be interrupted as intended, thus potentially blocking the channel mutex for a long time. However, it is believed that this bug did not result in incorrect behavior.
The fourth bug concerned a component that provides a queue that is time bounded, meaning that elements that have been added to the queue some time ago, but have not been removed yet, are automatically removed when new elements are added. Due to a bug in the algorithm that takes care of automatically removing such elements, an exception would be thrown if all elements in the queue were considered old and thus marked for removal. This lead to an exception when samples were added to the write queue, but the write queue was not processed for a long time and no new samples were added in this period of time. In this case, the exception would occur when new samples were finally added to the queue. Typically, such a situation would only occur when the system was under extremely high load, resulting in samples neither being written nor new samples being added to the queue for more than 30 seconds.
The bugs fixed in this release only concern internal implementation details. This means that data written by previous releases is correct and does not have to be regenerated or updated.
The Cassandra PV Archiver 3.1 adds a few new features and updates its dependencies to their respective newest versions. It is compatible with the Cassandra PV Archiver 3.0.x, meaning that it can operate on data stored by the Cassandra PV Archiver 3.0.x and the APIs supported by the Cassandra PV Archiver 3.0.x are fully supported.
The following features have been added in this release:
- A web-service API for managing the server has been added. This API is described in detail in Appendix C, Administrative API.
- The administrative user-interface now uses AJAX to load the list of channels asynchronously. This improves the performance when displaying a list containing a large number of channels.
There also are some bugfixes and minor improvements:
- For each module containing Java code, a source JAR is generated in addition to the binary JAR.
-
A
NullPointerExceptionthat could occur when updating a channel while concurrently moving or deleting it has been fixed. - The launcher script on Windows now works correctly when the path where the Cassandra PV Archiver is installed contains spaces.
- All library dependencies have been updated to their newest versions.
Version 3.1.1 is a bugfix release that fixes an issue with displaying the channel state in the channel list.
Unfortunately, a regression was introduced shortly before the release of version 3.0.0. This regression caused the state of a channel not to be visible in the list view (but it would show on the details page for a channel). This problem is fixed in version 3.0.1 so that the state now is also visible in the list view (like it was in older versions).
Version 3.1.2 is a bugfix release that includes an updated version of the EPICS Jackie library and brings a few minor improvements:
- EPICS Jackie has been updated to version 1.0.2. This version includes a fix for a bug that could cause connectivity issues for channels that are hosted by servers based on older EPICS versions.
- When an archive configuration command fails, the corresponding exception is now logged in the logfile. Expected exceptions (e.g. trying to add a channel that already exists) are logged with the level INFO, while unexpected exceptions (e.g. database errors) are logged with level ERROR. Such errors were already reported to the user through the user interface, but the logged exception (including the stack trace) might give additional insights into the actual cause of the error.
- Write timeouts when creating, updating, or deleting a “pending channel operation” are now handled more gracefully. These timeouts caused configuration commands to fail with a message like “Cassandra timeout during write query at consistency SERIAL…”. While the throttling options should still be used to avoid overloading the server, the new logic can help in handling short spikes by retrying an operation that timed out after a short delay. Configuring the throttling at a reasonable value is still needed because this mechanism will not work in a situation where the database is overloaded for a longer period of time (the operation will simply fail after reaching the maximum number of retries).
- The timeout for inter-node communication has been increased. When running a large number (typically thousands) of configuration commands that affected a remote server, the commands would fail with a timeout error due to the HTTP communication timing out. While this timeout would be reported to the user, the commands would still continue running in the background. The timeout for the HTTP communication has now been increased to 15 minutes, so that the HTTP connection should not time out, even when a large number of commands is processed.
Version 3.1.3 is a bugfix release that includes an updated version of the EPICS Jackie library and one minor improvement:
- EPICS Jackie has been updated to version 1.0.3. This version includes a fix for a bug that would cause connections to channels providing large values (waveforms with many elements) to fail. As a side effect, this bug would also cause the connections for all other channels hosted by the same server to be disrupted.
- A few minor improvements have been added to the changes regarding timeouts when creating, updating, or deleting a “pending channel operation” that have been added in the last release. This means that the code should now recover from timeouts in a few more cases.
The Cassandra PV Archiver 3.2 adds a few new configuration options and updates its dependencies to their respective newest versions. It is compatible with the Cassandra PV Archiver 3.1.x, meaning that it can operate on data stored by the Cassandra PV Archiver 3.1.x and the APIs supported by the Cassandra PV Archiver 3.1.x are fully supported.
Due to newly introduced configuration options, configuration files for version 3.2.x are not compatible with version 3.1.x. However, configuration files for version 3.1.x remain compatible with version 3.2.x.
The following improvements have been made in this release:
-
The memory consumption when generating decimated samples based on
pre-existing source samples has been reduced significantly.
This is important when adding new decimation levels to a large
number of channels.
In earlier versions, the sample decimation process could allocate
so much memory that the heap space would be exhausted, resulting in
an
OutOfMemoryError. Two new configuration options have been introduced for controlling the memory consumption of the sample decimation process:throttling.sampleDecimation.maxFetchedSamplesInMemoryandthrottling.sampleDecimation.maxRunningFetchOperations. -
The implementation of
AbstractObjectResultSethas been improved in order to avoid unnecessary copy operations. This change should improve the performance when reading samples from the database. In order to profit from this change, control-system supports usingAbstractObjectResultSetfor implementing their sample result sets should change the result set’sfetchNextPage()method to return aSizedIteratorinstead of a regularIterator. This change has already been implemented for theResultSetBasedObjectResultSet, so control-system supports using this class (like the Channel Access control-system support) will automatically profit from this improvement. -
The
cassandra.fetchSizeoption has been introduced in order to control the default fetch size used for queries. Usually, the default fetch size of the Cassandra driver should be fine, but users wanting to fine-tune the fetch size can now do so. -
The
server.interNodeCommunicationRequestTimeoutoption has been introduced in order to control the timeout for requests sent from one archiving server to another one. This timeout has been significantly increased in version 3.1.2, but now it is possible to increase it even further if necessary or to choose a shorter timeout if sufficient. - The way how the throttling of statements executed on the Cassandra cluster is handled has been improved. In older versions, the limit for read statements would only apply for the initial execution of a statement. If a statement later fetched more results (because there were more rows than the configured fetch size), this fetch operation would not count towards the limit. Now, a fetch operation is treated like a read statement and fully counts towards the limit. This means that in certain situations it might be possible to slightly raise the limit for read statements.
- The naming scheme for the MBeans exposed via JMX has been changed so that all MBeans of the archiving server are in a single domain. This means that clients using JMX to monitor the archiving server have to be changed to use the new object names. The JMX interface is not considered a public API and thus might again change in future versions.
There also was one bug that has been fixed in this release:
-
The way how write operations to the
generic_data_storetable were handled was unsafe because light-weight transactions (LWTs) were mixed with regular updates. This could theoretically lead to invalid data if writes were happening very rapidly or server clocks had an extremely large clock skew. As data is only rarely written to this table (once when the archiving cluster is initialized and every time the administrator’s password is changed), this bug was very unlikely to cause any actual problems.
The Cassandra driver has been updated to version 3.2.0 in this release.
That version includes a change to how user-defined types (UDTs) are
handled when using the schema builder to create a table.
Control-system supports using the schema builder to create a table with
UDT columns might have to be changed to use the schema builder’s
addUDTColumn(…) method with a parameter
constructed using SchemaBuilder.frozen(…) instead of
using addColumn(…) with an instance of
UserType.
The Cassandra PV Archiver server is the central component of the archiving system. It is responsible for monitoring process variables (channels in the terminology of the Cassandra PV Archiver) for changes and writing these changes to the archive. At the same time, it is also responsible for providing access to the data stored in the archive through a web-service interface. This chapter explains how to install, configure, and use the Cassandra PV Archiver server.
The Cassandra PV Archiver server is a pure Java application. This means that it can run on any platform providing the Java 7 Standard Edition or a newer version of the Java runtime environment (JRE). Even though the JRE is sufficient for running the Cassandra PV Archiver server, users are encouraged to install the Java Development Kit (JDK) because of the additional diagnostics tools it provides.
The Cassandra PV Archiver server has been tested on Linux, OS X, and Windows. On some of these platforms, it might make use of the JNA library for accessing platform-specific functions. However, the availability of these functions is not critical for the operation of the Cassandra PV Archiver server.
In addition to the JRE or JDK, an Apache Cassandra cluster is needed. Users that want to setup an Apache Cassandra cluster are encouraged to check out the Cassandra distributions available at Planet Cassandra. The Cassandra PV Archiver server is compatible with Cassandra 2.2 and 3.x. Most likely, it is also going to be compatible with newer versions of Cassandra.
![[Warning]](docbook/images/warning.png) | Warning |
|---|---|
Apache Cassandra 3.0.0 through 3.0.8 and 3.1 through 3.7 have a bug that affects the Cassandra PV Archiver. This bug can cause serious issues when deleting or renaming channels. The symptoms are channels appearing in some views and missing in others, even channels that have been added after deleting some other channels. For this reason, it is strongly recommended to avoid the affected versions of Apache Cassandra. The bug has been fixed in versions 3.0.9 and 3.8.0. Apache Cassandra 2.2.x should not be affected either. When using one of the affected version of Apache Cassandra, avoid deleting or moving channels until you have upgraded to a version of Apache Cassandra that is not affected. |
In the simplest case, the Cassandra cluster may consist of only a single node running on the same system as the Cassandra PV Archiver server. In general, it is a good idea to colocate Cassandra PV Archiver server nodes and Apache Cassandra nodes on the same set of computers, but technically speaking, there is no need for such a setup and the two software components can safely be separated into two sets of computers if this is preferred for administrative reasons.
Installing the JRE or JDK and the Cassandra cluster is outside the scope of this document. Readers are encouraged to refer to the documentation of the JRE / JDK of their choice for installation instructions. On most Linux distributions, choosing the JRE / JDK available from the distributions’s repositories is typically the best choice. For setup instructions for Apache Cassandra, please refer to the Cassandra documentation provided by DataStax.
For operation of both Apache Cassandra and the Cassandra PV Archiver server, it is critical that the clocks of all servers are well synchronized. In an Apache Cassandra database, a large clock skew can lead to data corruption. The administrator should take appropriate means for synchronizing the servers’ clocks and monitoring the clock skew.
The setup of a proper clock synchronization solution is outside the scope of this document. As a minimum, it is suggested that the administrator provides at least two NTP servers with which all servers are synchronized. These servers should be synchronized with each other and with some external reference, preferably a set of low-stratum NTP servers or even a GPS clock. NTP servers should typically run on physical hosts, not inside virtual machines. Many virtual machine solutions do not provide an adequately stable clock, so that NTP servers might be unreliable when running inside a virtual machine.
The Cassandra PV Archiver server contains some rudimentary clock skew monitoring system that tries to detect the clock skew between the servers. When this system detects that the clock of a server is skewed by more than 800 ms, it logs a warning. When it detects that the clock is skewed by more than 1200 ms, it immediately kills the server. The server is also killed when the monitoring process detects that the server’s clock skipped back in time.
Due to inherent limitiations of the implementation (for example using a TCP based protocol), this mechanism will typically underestimate the actual clock skew. For this reason, it is suggested that additional means are used for monitoring the clock skew and the mechanism provided by the Cassandra PV Archiver server is only considered a “last line of defense” in case all other mechanisms fail.
The Cassandra PV Archiver server is provided in two forms of distribution: The first one is a binary archive that can be used on Windows and most Unix-like platforms. The second one comes in the form of a Debian package. This Debian package has been designed to work on Ubuntu 14.04 LTS and Ubuntu 16.04 LTS. Most likely it is also going to work on most other modern, Debian-based distributions, as long as they use Upstart or systemd. The Debian package does not provide a traditional System-V style init script, so it will not work on distributions using this kind of init system.
When installing the Debian package, the package scripts take care of
creating a user and group with the names
cassandra-pv-archiver and registering the server with
the init system.
This means that after installing the package, the
cassandra-pv-archiver-server job is automatically
started with the privileges of that user.
When using the binary distribution, users have to take care of manually creating a user and group for running the server and also have to register the server with their init system. It is possible to run the the server as an existing user or even as the root user, but for a production setup, using a separate user is strongly encouraged for security reasons.
When using the binary distribution (and not the Debian package), the
start script for running the archive server is located in the
bin directory and is called
cassandra-pv-archiver-server
(cassandra-pv-archiver-server.bat on Windows).
The server runs in the foreground, so the terminal that is running the
server has to be kept alive.
When installing the Cassandra PV Archiver for the first time, the
keyspace used for storing data has to be created in the Cassandra
cluster.
The default name for the keyspace is pv_archive.
You can choose a different name, but in this case the name has to be
explicitly specified in the configuration file of the Cassandra PV
Archiver server.
In order to create the pv_archive keyspace in a
single node cluster, you can run the following command in the CQL shell
(cqlsh):
CREATE KEYSPACE pv_archive
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '1'};
When using a multi-node cluster, you typically do not want to use the
SimpleStrategy for replication and the replication
factor should be at least three.
Please refer to the
Cassandra documentation
provided by DataStax for details.
| Note |
|---|---|
When enabling authentication for the Cassandra cluster, ensure that the user used for the Cassandra PV Archiver server has full write access to its keyspace. In particular, it has to be able to create tables and query and modify data.
For this purpose, the user at least needs the
|
When using a local, single-node Cassandra setup with the default keyspace name and not requiring authentication, the default configuration should be fine for getting started. Otherwise, please refer to Section 3, “Server configuration”.
Once the server has been started, its administrative web-interface is available on port 4812 (unless the port number has been changed in the configuration file). Please refer to Section 4, “Administrative user interface” to learn more about using the administrative interface.
The configuration options used by the Cassandra PV Archiver server are
controlled through a configuration file in the
YAML format.
The configuration file is located in the conf
directory of the binary distribution or in the
/etc/cassandra-pv-archiver directory when using the
Debian package.
In either case, the configuration file is called
cassandra-pv-archiver.yaml.
It is not an error if the configuration file does not exists at the
expected location.
In this case the server starts using default values for all
configuration options.
The path to the configuration file can be overridden by specifying the
--config-file command line option to the
cassandra-pv-archiver-server script.
When this configuration option is specified, the default location is not
used.
Unlike the configuration file in the default location, a configuration
file specified with --config-file option must exist
and the server does not start if it is missing.
The configuration options are organized in a hierarchy. For the rest of this document, the first level of this hierarchy is called the section. The hierarchical path to a configuration option can either be specified inline or through indentation. For example, specifying
level1a:
option1: value1
level2:
option1: value2
level1b:
option1: value3
is equivalent to specifying
level1a.option1: value1 level1a.level2.option1: value2 level1b:option1: value3
The default values specified in this document are the default values that are used when a configuration option is not specified at all, not the value of the option that is specified in the configuration file distributed as part of the binary distribution or Debian package.
This section only describes the part of the configuration that is stored in the per-server configuration file, not the configuration that is stored in the database. Regarding the latter one, please refer to Section 4, “Administrative user interface”.
The cassandra section configures the server’s
connection to the Cassandra cluster.
The cassandra.hosts option specifies the list
of hosts which are used for initially establishing the connection
with the Cassandra cluster.
This list does not have to contain all Cassandra hosts because all
hosts in the cluster are detected automatatically once the
connection to at least one host has been established.
However, it is still a good idea to specify more than one host here
because this will ensure that the connection can be established
even if one of the hosts is down when the Cassandra PV Archiver
server is started.
By default, the list only contains localhost.
The list of hosts has to be specified as a YAML list, using the
regular or the inline list syntax. For example, a list specifying
three hosts might look like this:
cassandra:
hosts:
- server1.example.com
- server2.example.com
- server3.example.com
The cassandra.port option specifies the port
number on which the Cassandra hosts are listening for incoming
connections (for Cassandra’s native protocol).
The default value is 9042, which is also the default value used by
Cassandra.
The cassandra.keyspace option specifies the name
of the keyspace in which the Cassandra PV Archiver stores its data.
The default value is pv_archive.
While strictly speaking mixed-case names are allowed, the use of
such names is discouraged because many tools have problem with them
and they typically require quoting.
For this reason, the keyspace name should be all lower-case when
possible.
The cassandra.username option specifies the
username that is specified when authenticating with the Cassandra
cluster.
When empty, the connection to the Cassandra cluster is established
without trying to authenticate the client.
The default value is the empty string (no authentication).
The cassandra.password option specifies the
password that is specified when authenticating with the Cassandra
cluster.
The password is only used when the username is not empty.
The default value is the empty string.
The cassandra.fetchSize option specifies the
default fetch size that is used when reading data from the Cassandra
database.
The fetch size specifies how many rows are read from the database in
a single page.
Specifying a larger value typically improves performance when
processing a query that returns many rows, but results in more
memory usage in both the database server and the client because the
full page of rows has to be kept in memory.
The default value is zero, which causes the default fetch size of the Cassandra driver to be used. As of version 3.1.4 of the Cassandra driver, that default fetch size is 5000 rows. If specified, this option has to be set to an integer between 0 and 2147483647.
The fetch size specified here is only used for queries that do not explicitly specify a fetch size.
The cassandra.useLocalConsistencyLevel option
specifies the consistency level that is used for all database
operations.
The default value is false.
This option only has an effect when the Cassandra cluster is
distributed across multiple data centers.
By setting this option to true, the
LOCAL_QUORUM consistency level is used where
usually the QUORUM consistency level would be
used.
In the same way, the LOCAL_SERIAL consistency
level is used instead of the SERIAL consistency
level.
This option must only be enabled if only a single data center makes modifications to the data and all other data centers only use the database for read access. In this case, enabling this option can reduce the latency of operations because the client only has to wait for nodes local to the data center. The most likely scenario is a situation where all nodes running the Cassandra PV Archiver servers are in a single data center, but there is a second data center to which all data is replicated for disaster recovery.
![[Important]](docbook/images/important.png) | Important |
|---|---|
Never enable this option when there is more than one data center that is used for write access to the database. In this case, enabling this option will lead to data corruption because operations that are expected to result in a consistent state might actually leave inconsistencies.
This option merely provides a performance optimization, so in case
of doubt, leave it at its default value of
|
The server section configures the archiving server
(for example the ID assigned to each server instance and on which
address and ports the archiving server listens).
While the address and port settings can usually be left at their
defaults the server’s ID has to be set.
Each server in the cluster is identified by a unique ID (UUID).
As this UUID has to be unique for each server, there is no
reasonable default value, but it has to be specified explicitly.
The server’s UUID can be specified using the
server.uuid option.
Alternatively, it can be specified by passing the
--server-uuid parameter to the server’s start
script.
| Important |
|---|---|
Starting two server instances with the same UUID results in data corruption, regardless of whether these instances are started on the same host or different hosts. For this reason, care should be taken to ensure that each UUID is only used for exactly one process. |
As an alternative to specifying the server’s UUID in the
configuration file or on the command line, it is possible to have a
separate file that specifies the UUID.
The path to this file can be specified with the
server.uuidFile option.
If this file exists, it is expected to contain a single line with
the UUID that is then used as the server’s UUID.
If this file does not exist, the server tries to create it on
startup, using a randomly generated UUID.
By default this option is not set so that the server expects an
explicitly specified UUID.
This option is particularly useful in an environment where servers
are deployed automatically and should thus automatically generate a
UUID the first time they are started.
The server.listenAddress option specifies the IP
address (or the hostname resolving to the IP address) on which the
server listens for incoming connections.
If it is empty (the default), the server listens on the first
non-loopback address that is found.
This means that typically, this option only has to be set for
servers that have more than one (non-loopback) interface.
The specified address is used for the administrative user-interface, the archive-access interface, and the inter-node communication interface. In addition to the specified address, the administrative user-interface and the archive-access interface are also made available on the loopback address.
This option should never be set to localhost,
127.0.0.1, ::1, or any other
loopback address because other servers will try to contact the
server on the specified address and obviously this will lead to
unexpected results when the address is a loopback address.
The server.adminPort option specifies the TCP
port number on which the administrative user-interface is made
available.
The default is port 4812.
The server.archiveAccessPort option specifies the
TCP port number on which the archive-access interface is made
available.
The default is port 9812.
The archive-access interface is the web-interface through which
clients access the data stored in the archive.
The server.interNodeCommunicationPort option
specifies the TCP port number on which the inter-node communication
interface is made available.
The default is port 9813.
Like the name suggests, the inter-node communication interface is
used for internal communication between Cassandra PV Archiver
servers that is needed in order to coordinate the cluster operation
(for example in case of configuration changes).
The server.interNodeCommunicationRequestTimeout
option specifies the timeout used for the communication between
nodes.
The timeout is specified in milliseconds.
If chosen too low, complex requests (e.g. a request to modify the
configuration of many channels when importing a configuration file)
may time out.
If chosen too high, requests will take a very long time before
timing out in case of a sudden server crash or network disruption.
The default value is 900000 milliseconds (15 minutes). Valid values are integer numbers between 1 and 2147483647.
The throttling section contains options for
throttling database operations.
The Cassandra PV Archiver server tries to run database operations in
parallel in order to reduce the effective latency of complex
operations (e.g. operations involing many channels).
However, depending on the exact configuration of the Cassandra cluster
(for example the size of the cluster, network bandwidth and latency,
hardware used for the cluster, load caused by other applications), the
number of operations that can safely be run in parallel might differ.
When running too many operations in parallel, this results in some of the operations timing out. This can be avoided by reducing the number of operations allowed to run in parallel. On the other hand, when operations never time out, one might try to increase the limits in order to improve the performance.
The limits can be controlled separately for read and write operations
and for operations touching the channels’ meta-data (for example the
configuration and information about sample buckets) and the actual
samples.
Operations modifying channel meta-data are typically carried out using
the SERIAL consistency level, so in this case write
operations typically are more expensive than read operations.
Thus the limit for write operations should be lower than the limit for
read operations.
In the case of operations dealing with actual samples, read operations
typically are more expensive than write operation (due to how
Cassandra works internally), so the limit for read operations shold be
lower than the limit for write operations.
| Note |
|---|---|
When trying to optimize the throttling settings, it can be helpful to connect to the Cassandra PV Archiver server via JMX (for example using JConsole from the JDK). The current number of operations that are running and waiting is exposed via MBeans, so that it is possible to monitor how changing the throttling parameters affects the operation. |
The
throttling.maxConcurrentChannelMetaDataReadStatements
configuration option controls how many read operations for channel
meta-data should be allowed to run in parallel.
Usually, these are statements reading from the
channels, channels_by_server,
and pending_channel_operations_by_server tables.
Typically, this limit should be greater than the limit set by the
throttling.maxConcurrentChannelMetaDataWriteStatements
option.
The default value is 64.
The
throttling.maxConcurrentChannelMetaDataWriteStatements
configuration option controls how many write operations for channel
meta-data should be allowed to run in parallel.
Usually, these are statements writing to the
channels, channels_by_server,
and pending_channel_operations_by_server tables.
Typically, such operations are light-weight transactions and thus
this limit should be less than the limit set by the
throttling.maxConcurrentChannelMetaDataReadStatements
option.
The default value is 16.
The
throttling.maxConcurrentControlSystemSupportReadStatements
configuration option controls how many read operations the
control-system supports (all of them combined) are allowed to run in
parallel.
Usually, these are statements that read actual samples and thus read
from the tables used by the control-system support(s).
Typically, this limit should be less than the limit set by the
throttling.maxConcurrentControlSystemSupportWriteStatements
option, but significantly greater than the limit set by the
throttling.maxConcurrentChannelMetaDataReadStatements
option.
The default value is 128.
The
throttling.maxConcurrentControlSystemSupportWriteStatements
configuration option controls how many write operations the
control-system supports (all of them combined) are allowed to run in
parallel.
Usually, these are statements that write actual samples (for each
sample that is written, an INSERT statement is
triggered) and that thus write to the tables used by the
control-system support(s).
Typically, this limit should be greater than the limit set by the
throttling.maxConcurrentControlSystemSupportReadStatements
option and significantly greater than the limits set by the
throttling.maxConcurrentChannelMetaDataReadStatements
and
throttling.maxConcurrentChannelMetaDataWriteStatements
options.
The default value is 512.
The
throttling.sampleDecimation.maxFetchedSamplesInMemory
configuration option controls how many samples may be fetched into
memory when generating decimated samples.
The sample decimation process might consume a lot of memory when generating decimated samples from already existing source samples for a lot of channels. The amount of samples that may be fetched into memory is directly connected to memory usage. Each fetched sample occupies about 1 KB of memory (for scalar Channel Access samples), so one million samples are roughly equivalent to 1 GB of memory.
As the exact number of samples returned by a fetch operation cannot
be known in advance, this threshold might actually be exceeded
slightly.
The
maxRunningFetchOperations
option can be used to control by how much the threshold may be exceeded.
The default value for this option is 1000000 samples.
The
throttling.sampleDecimation.maxRunningFetchOperations
configuration option controls how many fetch operations may run in
parallel when generating decimated samples.
As the exact number of samples returned by a fetch operation cannot
be known in advance, the threshold set by the
maxFetchedSamplesInMemory
option might actually be exceeded slightly.
This configuration option can be used to control by how much the
threshold may be exceeded.
The max. number of running fetch operations multiplied by the
fetch size
is the max. number of samples by which the limit might be exceeded.
The default value for this option is 20.
The controlSystemSupport section contains the
configuration options for the various control-system supports.
For each available control-system support, this section has a
corresponding sub-section.
The configuration options in these sub-sections are not handled by
the Cassandra PV Archiver server itself but passed as-is to the
respective control-system support.
For this reason, the names of the available options entirely depend
on the respective control-system support.
Please refer to the documentation of the respective control-system
support for details.
For example, the documentation for the Channel Access control-system
support is available in Appendix D, Channel Access control-system support.
The Cassandra PV Archiver server is based on the Spring Boot framework. For this reason, the options supported for configuring logging are actually the same ones that are supported by Spring Boot. These options are documented in the Spring Boot Reference Guide. The Cassanra PV Archiver server uses Logback as its logging backend, so the specifics of how to configure Logback for Spring Boot might also be interesting.
In order to get started more easily, this section contains a few pointers on how the logging configuration can be modified.
The log level can be set both globally and for specific subtrees of the class hierarchy. When specifying different log levels for different parts of the hierarchy, more specific definitions (the ones covering a smaller sub-tree of the hierarchy) take precedence over more general definitions.
The available log levels are ERROR,
WARN, INFO,
DEBUG, and TRACE.
Each log level contains the preceding log levels (for example
the log level INFO also contains
ERROR and WARN).
The log level for the root of the hierarchy (that is used for all
loggers that do not have a more specific definition) is set through
the logging.root.level option.
By default, this log level is set to INFO.
This results in a lot of diagnostic messages being logged, so you
might want to consider reducing it to WARN.
The log level for individual parts of the hierarchy can be set by
using a configuration option containing the path to the respective
hierarchy level.
For example, in order to enable DEBUG messages for all classes in
the com.aquenos.cassandra.pvarchiver package (and
its sub-packages), one could set
logging.com.aquenos.cassandra.pvarchiver.level to
DEBUG.
The path to the log file can be specified using the
logging.file option.
If no log file is specified (the default),
log messages are only written to the standard output.
In order to log to more than one log file (for example depending
on the log level or the class writing the log message) or in order
to disable logging to the standard output, one has to specify a
custom logback configuration file (see the next section).
When the configuration options directly available through the
Cassandra PV Archiver server configuration-file are not sufficient,
one can specify a custom Logback configuration file.
The path to this file is specified using the
logging.config option.
The
information
available in the
Spring Boot Reference Guide
might be useful when using this option.
In addition to the configuration options that can be specified in the
server’s configuration file, there are two environment variables that
can be passed to the server’s startup script.
When using the Debian package, these environment variables should be
set in the file
/etc/default/cassandra-pv-archiver-server.
The first environment variable is JAVA_HOME.
It specifies the path to the JRE.
When starting the Java process, the server’s startup scripts uses the
$JAVA_HOME/bin/java executable
(%JAVA_HOME%/bin/java.exe on Windows).
When JAVA_HOME is not set, the startup script uses the
java executable that is in the search
PATH of the shell executing the startup script.
The second environment variable is JAVA_OPTS.
When set, the value of this environment variable is added to the
parameters passed to the java executable.
It can be used to configure JVM options like the maximum heap size.
The administrative user interface (UI) is provided in form of a web UI.
It is available for each Cassandra PV Archiver server and (if the port
has not been changed manually) can be accessed at
http://myserver.example.com:4812/.
The administrative UI is the main point for monitoring the operation of the Cassandra PV Archiver cluster and configuring archived channels. Unlike the server’s configuration file (see Section 3, “Server configuration”), which usually is only setup once and then rarely changes, the admin UI is used for regular configuration tasks like adding, modifying, and removing channels. All these configuration changes take effect immediately and do not require a restart of the Cassandra PV Archiver server. All channels can be configured through the UIs of all Cassandra PV Archiver servers, regardless of which server actually archives the respective channel.
For all functions of the administrative UI to work correctly, JavaScript has to be enabled in the browser. Due to the extensive use of JavaScript, CSS 3, and web fonts, only fairly modern versions of most browsers are supported. In particular, Microsoft Internet Explorer is only supported starting with version 11.
The UI is divided into four sections which can be acccessed through the navigation bar at the top of the UI (see Figure III.1, “Administrative UI navigation bar (full screen size)”). On very narrow screens (e.g. on smartphones), the navigation bar is hidden and has to be opened by pressing the button with the three horizontal bars (see Figure III.2, “Administrative UI navigation bar (small screens)”).


The dashboard provides an overview of the Cassandra PV archiver server and cluster status. The server status is the only part of the administrative UI that is actually different on each of the servers. When logged in with administrative privileges, the UI has the option to remove servers from the cluster view when they have been offline for some time.
The channels section is the section through which the status of archived channels can be monitored and through which their configuration can be changed. This section is discussed in more detail in Section 4.2, “Managing channels”. The about section provides information about which version of the Cassandra PV Archiver server is running. Finally, the sign in section allows for signing in to the UI in order to show elements that require administrative privileges. In general, all actions that change the configuration require administrative privileges, while all functions that do not affect the Cassandra PV Archiver server’s operation can be used without having to sign in. When the user is already signed in, the current username and the option to sign out are displayed instead of the sign in button.
When signing in to the administrative UI, one has to specify a
username and a password.
The Cassandra PV Archiver server automatically creates an
administrative user with the username admin and the
password admin (case sensitive).
After having signed in for the first time, the password can be changed
by selecting the corresponding link from the menu that opens when
clicking on the username in the navigation bar (see
Figure III.3, “Changing the password”).
The credentials are stored in the Cassandra database, so signing in and changing the password is only possible while the server is connected to the Cassandra cluster.
The channels section of the administrative UI provides functions for monitoring and configuring channels. There are two different views how channels can be displayed. The “All Channels” view shows all channels that exist in the whole cluster. The other view is opened by selecting a specific server and only shows the channels that are hosted by that server. While mostly these two views provide the same functionality, there are two fundamental differences:
The “All Servers” view displays all channels for the whole cluster. For this reason, it does not display the status of each channel. The status of a channel is only known by its server and collecting the status of all channels could take a very long time when there are many servers. For this reason, the status of a channel is only displayed in the per-server view or when selecting a specific channel.
The other difference concerns the import and export of configuration files. Configuration files always contain the channels managed by a certain server. For this reason, the import and export functions are only available from the per-server view.
A channel can be added by clicking on the button displayed above the channel list. This button is only shown when the user is signed in and has administrative privileges. When adding a channel, a number of options can be specified, a few of them being mandatory (see Figure III.4, “Add channel view”).
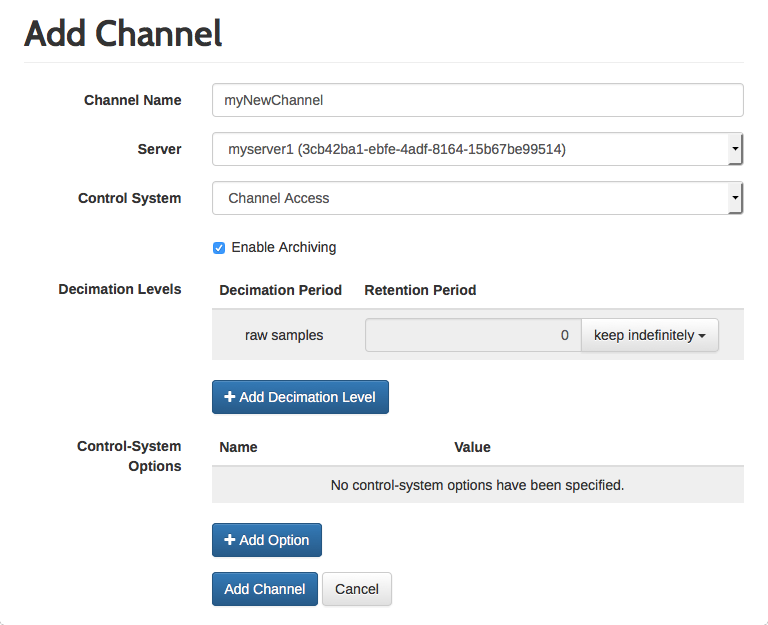
The channel name is mandatory and specifies the name under which the channel is going to be identified in the cluster. For this reason, the channel name has to be unique within the whole cluster. Typically, the channel name is also the name that is used by the control-system support when trying to monitor the corresponding process variable. However, some control-system supports may choose to specify this information separately.
Selecting a server that hosts the channel is also mandatory. This means that this server is responsible for managing the channel, starting the control-system support and initializing it with the channel’s configuration when the server goes online. When opening the “Add Channel” view from the per-server view, this option is already set to point to the respective server. When opening it from the “All Channels” view, the server has to be selected.
The “Control System” option is mandatory and specifies the control-system support for the channel. Unlike all other options, this option cannot be changed after creating the channel and is fixed until the channel is deleted (also deleting all samples that have been archived for the channel). The reason for this restriction is that the format of the archived data depends on the control-system support and there is no generic way how data archived by one control-system support could be converted to the format required by another control-system support.
The “Enable Archiving” flag is enabled by default. This means that the control-system support for the channel is initialized when the server hosting the channel goes online. When disabling this option, the control-system support is not started, but apart from this the channel can be used like any other channel. In particular, decimated samples (if configured) are still being generated and the archived samples can be accessed. Disabling archiving is useful when a channel is not used any longer (for example because the corresponding process variable has been removed from the control-system), but its data might still be useful for historic purposes. As long as archiving is disabled, no new samples are going to be archived for the channel, even if the corresponding process variable still exists and is active.
The “Decimation Levels” section of the “Add Channel” view defines which decimation levels exist and how long their retention period is. Please refer to Chapter I, Overview of Cassandra PV Archiver, Section 3, “Decimated samples” for an introduction to the concept of decimation levels. The retention period specifies how long samples are kept before they are deleted. A sample is deleted when the difference between its time stamp and the time stamp of the newest sample that exists in the same decimation level is greater than the specified time period. As only complete sample buckets are deleted, a sample might actually be kept a bit longer than the specified amount of time.
A retention period of zero specifies that samples in the respective decimation level are supposed to be kept indefinitely. Each decimation level must have a retention period that is greater than or equal to the retention period of all decimation levels with a shorter decimation period. This also means that the retention period of all decimation levels has to be greater than or equal to the retention period of the raw samples. As a retention period of zero specifies indefinite retention, it is considered greater than all other retention periods.
The “Control-System Options” sections of the “Add Channel” view allows for specifying configuration options that are passed to the control-system support as-is. Control-system options are not verified except for checking that each control-system option is only specified once. However, specifying a control-system option that is not supported by the corresponding control-system support or specifying an invalid value for a supported option can result in the control-system support reporting an error when the channel is initialized. In this case, the channel is put into an error state and archiving is disabled until the configuration is fixed.
As the support for control-system options entirely depends on the respective control-system support, please refer to the control-system support’s documentation for a list of supported options. The documentation for the Channel Access control-system support can be found in Appendix D, Channel Access control-system support.
After clicking the administrative UI verifies that the specified options are valid. If there is an error, the “Add Channel” view is shown again with the problematic fields being marked. Otherwise, the channel is added immediately and the details view for the newly created channel is shown.
A channel’s configuration and status can be inspected by clicking on the channel name in the channel list. In addition to the channel’s configuration some status information is shown. Which information is shown depends on the channel’s state.
Typically, the channel’s state (OK, Disabled, Disconnected, or Error) is shown. If the channel is in the error state, an error message is shown too. In addition to that, the number of samples that have been dropped, that skipped back in time, and that have been written is shown. These numbers are counted since the last time the channel has been initialized. A channel is initialized when its server goes online and when its configuration is changed.
The number of samples dropped is the number of samples that were queued by the control-system support for archiving, but actually were not written to the archive because there was an overflow of the queue. Samples are queued for up to thirty seconds. After this time, they are removed from the queue when new samples arrive. This mechanism helps to avoid a denial of service due to unbounded memory consumption when a control-system support constantly queues samples more quickly they can be written. This number might be non-zero due to load peaks, in particular during server startup. However, when it grows constantly, this is an indication that the control-system supports writes too many samples and either the sample rate should be reduced or the server load should be reduced by archiving fewer channels on this server (and possibly increasing the number of database servers).
The number of samples that skipped back in time typcially is very small. It counts the number of samples that were queued by the control-system support for archiving, but actually were not written because they had a time stamp less than or equal to the time stamp of the most recent sample. Such a situation typically occurs when a channel is initialized and the control-system support tries to archive a sample that has already been received before. A similar situation can occur when the control-system support loses its connection to the underlying control-system and reestablishes it later. When this number grows constantly, it can indicate a problem with the clock that is used for the sample’s time-stamp.
The number of samples written is exactly what the name suggests. It counts the samples that have actually been successfully written to the database.
When signed in with administrative privileges, the channel details view also provides buttons for modifying the channel’s configuration These buttons are shown at the top of the view, above the channel’s status.
After adding a channel, its configuration can be changed. In order to change the configuration, one first opens the channel’s details view and then clicks on the button. Modifying a channel’s configuration requires administrative privileges.
The “Edit Channel” view is very similar to the “Add Channel” view, the main difference being that the channel name, the server, and the control-system cannot be changed. A channel can be moved to a different server and its name can be changed, but these actions cannot be triggered from the “Edit Channel” view, but are handled separately. A channel’s control-system must be specified when adding the channel and cannot be changed later.
Care should be taken when modifying retention periods: When decreasing the retention period of a decimation level (or the raw samples), samples that are older than the time specified by the new retention period might get deleted immediately. The deletion of old samples happens asynchronously, so there is a small chance that samples might be retained for a short moment before actually being deleted, but one cannot rely on that.
When removing a decimation level, the corresponding samples are deleted immediately and cannot be recovered. When the decimation level is added back later, the decimated samples have to be generated again. When the decimation level of the samples used as the source for generating the decimated samples has a shorter retention period than the decimation leve that has been removed and readded, it is possible that not all decimated samples can be generated again and thus data is lost unrecoverably.
When changing a channel’s configuration, archiving of the channel has to be stopped for a short amount of time in order to apply the configuration changes. This happens automatically and typically takes less than a second.
When a channel is not needed any longer, it can be removed from the archive. Removing a channel results in the immediate deletion of all its data (including all samples). When a channel should not be archived any longer, but the existing data should be kept, the channel should not be removed, but it should only be disabled. A channel can be disabled by editing its configuration.
In order to remove a channel, one first has to go to the channel’s details view. In the details view, one can click on the button, and after confirming that the channel should in fact be removed, the channel and all its data are deleted immediately.
Removing a channel requires administrative privileges.
It is possible to move a channel to a different server and to rename an existing channel. Both functions are available from the channel’s details view.
For moving a channel, one clicks on the button and after selecting the server to which the channel shall be moved, it is shutdown and on the old server and brought back up on the new one. In order to compensate for potential clock skew between different servers, archiving for the channel has to be disabled for some time, but this should typically not take longer than 30 seconds.
For renaming a channel, one clicks on the button and enters the new name for the channel. The new name must be a name that is not already used for a different channel. After entering the name and confirming, the channel is renamed. Renaming the channel involves copying some meta-data, which might take a few seconds. Archiving is disabled while the rename operation is in progress and is automatically started again once the operation has finished.
Moving or renaming a channel requires administrative privileges.
When adding or modifying a large number of channels at the same time, the import function can be useful because it allows for using external scripts for generating a configuration file that can then be imported into the Cassandra PV Archiver.
The import function can be accessed by clicking on the button in the channels overview. The button is only available in the per-server view, not in the “All Channels” view. The reason is that the configuration format does not allow for specifying a server for each channel and thus the server needs to be specified for all channels when importing the file.
The configuration file has to be supplied in an XML format.
The XML namespace URI for the channel configuration is
http://www.aquenos.com/2016/xmlns/cassandra-pv-archiver-configuration
and the format is specified by an
XML Schema file.
When importing a configuration file, one can specify which kind of actions should be taken. One can choose to add channels that exist in the configuration file, but do not yet exist in the Cassandra PV Archiver configuration. One can also choose to update channels that already exist, but have a different configuration in the configuration file. Finally, one can choose to remove channels that exist in the server’s configuration, but not in the configuration file. The last option is particularly dangerous because it results in channels being removed unrecoverably without further confirmation.
If a channel that is specified in the configuration file already exists, but is managed by a different server or uses a different control-system support, it is not touched. A channel’s control-system support cannot be changed and moving a channel to a different server is only supported through the explicit move function.
Importing channel configurations requires administrative privileges.
The configuration of all channels managed by a server can be exported into a configuration file. This is mainly useful for using such a file as a template for generating a configuration file that can then be used with the import function. However, it might also be useful to save a certain configuration state outside of the database in case one want to return to this configuration at a later point in time.
In order to export the current configuration, one has to go the channels overview. The export function is only available from the per-server view, not the “All Channels” view. In the channels overview, one has to click on the button. This results in an XML file being generated that can then be saved to the user’s hard disk. The generated file conforms to the format that is required by the import function.
This section gives some hints on how to fix certain problems that might appear while running the Cassandra PV Archiver server. Readers may skip this section and come back later in case they experience one of the problems.
Apache Cassandra limits the time that is spent trying to process a statement. When a statement cannot be processed within this time limit, it fails with a timeout error. Such an error might appear in the form of a message like “Cassandra timeout during write query at consistency SERIAL…” or a similar message being displayed when trying to apply configuration changes or being displayed as the error message for a channel that is in the error state.
Typically, statements time out because the Cassandra cluster is
overloaded with requests and thus cannot process all of them in a
timely manner.
In this case, reducing the number of statements that are run in
parallel can help alleviate the problem.
When a write statement with a consistency level of
SERIAL fails, this is most likely caused by the
throttling.maxConcurrentChannelMetaDataWriteStatements
option having a too large value.
Please refer to Section 3.3, “Throttling” for
details regarding the throttling of concurrent statements.
Timeouts when reading data might also occur because of too many tombstones being present. In this case, there typically is a coressponding message in the log file of the Cassandra server. Please refer to Section 5.4, “Too many tombstones” for details about handling tombstones.
There are two ways how channels can be listed: All channels in the cluster can be listed or only the channels managed by a certain server can be listed. It can happen that these two lists get out of sync, so that channels are shown in the list of all channels, but not in the list for a specific server.
The reason for this is that the two lists are retrieved in different ways. The all channels list is generated by getting the channels from the database (technically speaking, there is a cache layer involved, but typically this layer is not responsible for the inconsistencies). The per-server list, on the other hand, is retrieved from the server’s in-memory configuration when the server is online.
When adding or removing channels fails, it can happen that the operation actually succeeded up to a point where the channel already exists in the database, but the server’s in-memory configuration has not been updated.
When a channel that has been removed still exists in the per-server list, but has been removed from the all channels list, forcing a reinitialization of the channel usually fixes the problem. When, on the other hand, a channel that has been added exists in the all channels list but is missing in the per-server list, the only way to solve this is by restarting the affected server.
Usually, either problem only occurs when some database operations fail due to a transient database problem or timeouts. Please refer to Section 5.1, “Timeouts” for more information about how to fix timeouts.
Some operations regarding channels (in particular configuration changes and the creation of new sample buckets) require special protection in order to avoid data corruption. Without this protection, data corruption could happen when the server crashes after the operation has started but before it has completed. Because of how Cassandra applies data changes and due to possible clock skew in distributed systems, this mechanism has to ensure that no other modification is attempted for a certain amount of time after such an operation failed.
This means that any further modifications (including the archiving of samples) are blocked for up to ten minutes after an operation has failed. When being initialized, the channel switches to the error state with an error message like “The channel cannot be initialized because an operation of type … is pending”. When trying to make changes to the channel’s configuration, a similar message is displayed.
There is only one way to resolve this issue: Waiting until the protection period has passed. Usually, the channel is automatically initialized again after the period has passed. Otherwise, a reinitialization can be triggered from the administrative UI.
There is a very similar message after moving a channel from one server to another. In this case, further modifications are also blocked in order to allow for some clock skew between servers. In contrast to the issue described earlier, the protection period is very short in this case and the channel is typically put back in operation after less than 30 seconds.
When deleting data from a Cassandra database, this data is actually not deleted immediately. Instead, special markers (so-called tombstones) are inserted in order to mark the data as deleted. Due to how Cassandra works internally, these tombstones might not be present on all nodes when some of the nodes were down while the data was being deleted. In this case, it is important that the tombstones are replicated to these nodes before they can safely be removed (together with the data thas has been marked as deleted).
The time how long tombstones are kept is configured in Cassandra by
setting the GC grace period.
It is very important that nodetool repair (which
ensures consistent replication) is run more frequently than the time
specified by the GC grace period.
After the GC grace period has passed, a failed node must not be
brought back online because this would result in deleted data suddenly
reappearing, which in the context of the Cassandra PV Archiver could
lead to data corruption.
When reading data, Cassandra has to keep all the tombstones it finds on the way, so that data presented by other nodes can be checked against these tombstones (because it might actually have been marked as deleted). Keeping track of these tombstones consumes memory on the coordinator node and affects performance, which is why Cassandra limits the number of tombstones that it allows before aborting a query. Even before hitting this limit, Cassandra starts logging a warning message to inform the user that a high number of tombstones has been detected. Such a message might look like “Read … live rows and … tombstone cells for query SELECT * FROM … WHERE server_id = … LIMIT 5000 (see tombstone_warn_threshold)”.
In the Cassandra PV Archiver, there are three tables where such a
problem is likely to appear: the
pending_channel_operations_by_server,
channels, and channels_by_server
tables.
The pending_channel_operations_by_server table
and (even though less likely) the
channels_by_server table are affected when a
large number of channels is modified, in particular when they are
added or removed.
The channels tables might be affected when a large
number of samples is deleted in a rather short period of time
(typically because samples are archived at a very high data rate).
In general, reducing the GC grace period is a good idea to avoid such a situation, but the GC grace period must only be reduced when anti-entropy repairs are run more often.
For problems with the
pending_channel_operations_by_server table, there
is a workaround that involves manually deleting all data from that
table.
Before using this workaround, one has to ensure that all Cassandra PV
Archiver servers have been shutdown for at least ten minutes (and stay
shutdown while applying the workaround) and all Cassandra database
nodes are up.
One can then use the following statement on the CQL shell after
switching to the keyspace used by the Cassandra PV Archiver:
TRUNCATE pending_channel_operations_by_server;
This statement deletes all data for this table, including all tombstones. This is why it is important that all Cassandra nodes are up and running. After applying this statement, the Cassandra PV Archiver servers can be started again.
When this problem appears for the
channels_by_server table, adding a new server and
moving all channels from the affected server to the new server can
help.
After this, the affected server can be brought up again with a new
UUID (the old UUID should not be reused in order to avoid hitting the
problem again).
When this problem appears for the channels table,
renaming the channel and then renaming it back to the original name
might help.
However, sometimes this workaround will not show any effect.
In this case, one can only wait until the GC grace period has passed.
The Cassandra PV Archiver server (and Apache Cassandra, too) relies on well-synchronized server clocks. When the clock skew between servers is too large or when the clock of a server skips back in time, this results in an error message like “The system clock of this server is skewed by at least … ms compared to server … - shutting down now” or “System clock skipped back - shutting down now”. In this case, one should check the mechanism (typically NTP) that is used for synchronizing the server clocks.
A clock that leaps forward should only be synchronized by slewing it, not by jumping back to an earlier point in time. Jumping back to an earlier point in time is problematic because Apache Cassandra decides which update has been applied last by checking the time stamp associated with the update. This means that going back to an earlier time can result in data being written, but being superseded by data that has been written earlier, but appears newer because of a more recent time stamp.
When trying to sign in to the administrative UI, one might get an error message like “You could not be signed in. Please check the username and password”. Typically, this message indicates that the username or password were wrong, but this message might also be displayed when they are actually correct. In this case, the reason is that the credentials cannot be verified because the server cannot read from the Cassandra database.
For this reason, when trying to sign in and presumably correct credentials are rejected, one should go the dashboard of the administrative UI and verify that the server is actually connected to the Cassandra database cluster.
When one cannot sign in to the administrative UI any longer because the password has been lost, one might have to reset this password. This can be done by connecting to the Cassandra database with the CQL shell, switching to the keyspace used by the Cassandra PV Archiver, and issuing the following statement:
DELETE FROM generic_data_store WHERE component_id = ad5e517b-4ab6-4c4e-8eed-5d999de7484f AND item_key = 'admin' IF EXISTS;
This deletes the entry for the admin user from the
database.
As this user is always assumed to exist, even if it is not in the
database, the Cassandra PV Archiver server will assume that it again
uses the default password admin.
After signing in using the default password, one can immediately
change the password back to a secure one.
Clients for the Cassandra PV Archiver allow users to query the archive, retrieving archived samples for each channel. For most users, the plugin for Control System Studio’s Data Browser (see Section 1, “Control System Studio”) is the easiest option for accessing the archive. However, other clients are supported as well through an open web-service interface. Please refer to Section 2, “Other clients” for details.
The Data Browser view of Control System Studio (CSS) provides powerful tools for finding, plotting, and exporting archived data. Integration with the Cassandra PV Archiver is provided by the JSON Archive Proxy client plugin. Please download the newest version of the JSON Archive Proxy that matches your version of CSS.
In order to install the plugin, the files from the
archive-json-reader-plugins directory in the
distribution archive have to be copied to the plugins
directory of the CSS installation.
The source files can, but do not have to be included.
For some versions of CSS, the plugin is detected automatically the next
time CSS is started.
For other versions, it is necessary to register the plugin manually
(e.g. by manually adding the two bundles to
configuration/org.eclipse.equinox.simpleconfigurator/bundles.info).
After starting CSS, the Cassandra PV Archiver has to be added as a data source. In the preferences, go to → → (see Figure IV.1, “CSS Data Browser options in the preferences tree”).
The archive URL has to be added to the list of
“Archive Data Server URLs” (see
Figure IV.2, “CSS Data Browser archive data server URLs”).
The URL is
http://server>:9812/archive-access/api/1.0/, where
<server> has to be replaced by the host name or
IP address of one of the archive servers of course.
The port is 9812 unless the archive access port has been changed in the
server’s configuration.
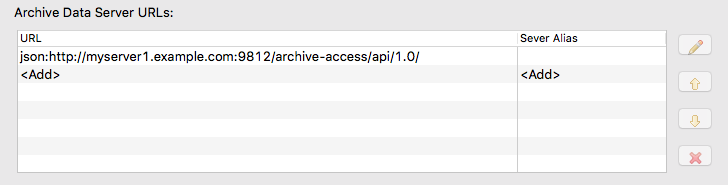
For a large installation, one should provide a load balancer that forwards requests, distributing them over the whole cluster. This also has the advantage that clients will still work when one of the servers is down. For the latter benefit, the load balancer itself has to be part of a high availability setup, of course.
In addition to adding the URL to the list of “Archive Data Server URLs”, it can also be added to the list of “Default Archive Data Sources” (see Figure IV.3, “CSS Data Browser default archive data sources”). Strictly speaking, this is not necessary for retrieving data from the archive, but it has the advantage that the archive can be used as a data source when no data source has been selected explicitly (e.g. when using historic data for a trend plot in a BOY panel). The key used for the Cassandra PV Archiver is always 1.
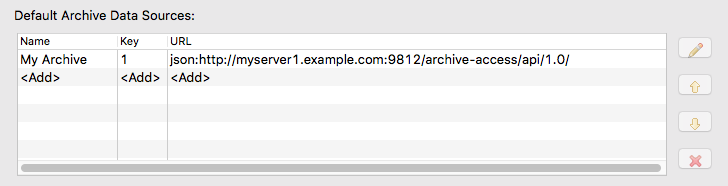
After adding the data source to CSS, CSS has to be restarted in order for the changes to take effect. After restarting, the archive can be accessed from the “Data Browser” perspective (see Figure IV.4, “CSS Data Browser perspective”).
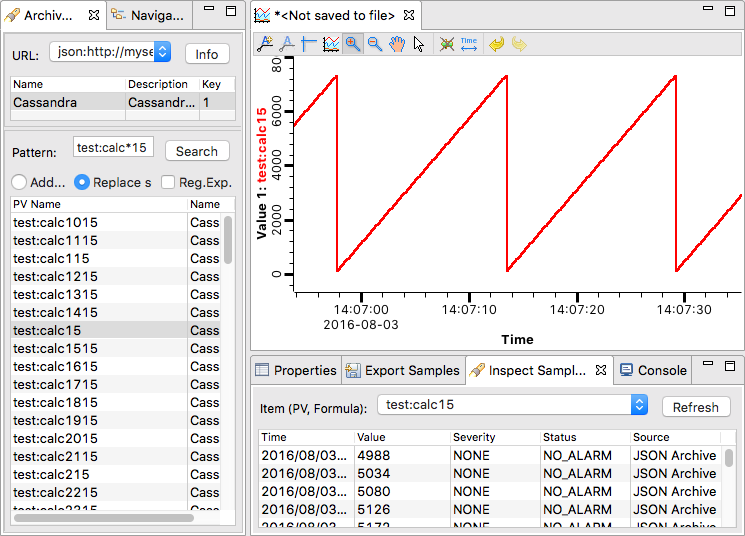
After seleting the archive URL from the list, one can search for
channels.
The search expression may contain glob patterns (e.g.
myC*5, myChannel?, etc.).
Alternatively, regular expression may be used.
The data for a channel can be plotted by right clicking it in the result
list and selecting
→
from the context menu.
When there is already an open trend plot, one can add additional
channels to this plot by simply dragging channels from the result list
and dropping them on the plot.
The data that is visible in the plot can also be examined through the “Inspect Samples” view. In addition to that, it can be exported into a file through the “Export Samples” view. When using the “Export Samples” view and selecting “Optimized Archived Data”, the most appropriate decimation level of the channel (the one which returns a number close to the requested number) is used. When selecting “Raw Archived Data”, only raw samples are used.
The web-service interface that is used for integrating with Control System Studio can also be used by other clients. The protocol used by this web-service is specified in Appendix B, JSON archive access protocol 1.0. At the moment, this protocol is limited to providing basic information (scalar and array samples of a limited set of types, including some meta-data). In the future this interface is going to be extended, so that it will be possible for each control-system support to use a custom data format.
For some applications, using the web-service protocol might not be a viable solution because the actual sample objects (as internally stored by the control-system support) are needed or high troughput for mass-processing data is required. In this case, there are two options.
The first option is writing a Java application that uses the
ArchiveAccessService (or rather its
implementation, the ArchiveAccessServiceImpl)
from the cassandra-pv-archiver-server module.
This will directly expose the sample objects as they are provided by the
control-system support.
The second option is directly accessing the Cassandra database. The layout of the tables (as far as samples are concerned) is described in Appendix A, CQL table layout. Applications accessing the database directly should only read data, never insert new data or update existing data. Ensuring data consistency in a distributed system is very tricky and it is very likely that third-party applications would break the data consistency guarantees carefully protected by the Cassandra PV Archiver.
The Cassandra PV Archiver has been designed to be modular, so that it can easily be extended. The standard distribution is built from five Maven modules:
- cassandra-pv-archiver-common
- cassandra-pv-archiver-control-system-api
- cassandra-pv-archiver-control-system-channel-access
- cassandra-pv-archiver-server
- cassandra-pv-archiver-server-app
The cassandra-pv-archiver-common module provides code
that is shared by most modules, in particular some utility classes.
For details please refer to the
API reference.
The cassandra-pv-archiver-control-system-api module
provides the API classes that have to be implemented by a control-system
support.
Please refer to Section 1, “Adding a control-system support” and the
API reference
for details.
The cassandra-pv-archiver-control-system-channel-access
module provides the control-system support for integration with Channel
Access based control-systems.
Please refer to Appendix D, Channel Access control-system support and the
API reference
for details.
The cassandra-pv-archiver-server module provides the
actual Cassandra PV Archiver server.
When building a custom server application, one will typically build on top
of this module.
For details please refer to the
API reference.
The cassandra-pv-archiver-server-app module bundles the
cassandra-pv-archiver-server module with the
cassandra-pv-archiver-control-system-channel-access
module.
This module can be used as an example of how to build a custom
distribution of the Cassandra PV Archiver server that contains additional
control-system supports.
Instead of using the existing code for accessing the archive, some applications might want to access the database directly. In this case, please refer to Appendix A, CQL table layout for details about the database structure.
The most common extension to the Cassandra PV Archiver is an additional control-system support. A control-system support provides the connectivity to a certain control-system so that process variables from that control-system can be archived. This section explains the basics of how a control-system support is implemented and registered with the Cassandra PV Archiver server. It is intended as an addendum to and not a replacement of the API reference, which should also be studied carefully.
The entry point for a control-system support is its implementation of
the
ControlSystemSupportFactory
interface.
Each control-system support has to provide such an implementation and
register it by adding the file
META-INF/cassandra-pv-archiver.factories to the class
path.
This file should contain a single entry for registering the
ControlSystemSupportFactory:
com.aquenos.cassandra.pvarchiver.controlsystem.ControlSystemSupportFactory = \ com.example.MyControlSystemSupportFactory
This file is a Java properties file and thus has to adhere to the syntax
expected by the java.util.Properties class.
In this example,
com.example.MyControlSystemSupportFactory is the
factory class for the new control-system support.
The factory class has to provide the prefix that is used to identify
configuration options in the controlSystem section of
the
server’s configuration file.
In addition to that, it provides a method for instantiating the actual
control-system support class (which has to implement
ControlSystemSupport).
While the factory needs to have a default constructor, the actual
control-system support can be initialized using the control-system
options that have been specified in the server’s configuration file.
The control-system support is identified by an identifier and a name. The identifier is used in configuration files (when importing or exporting channels) and in the database. The name, on the other hand, is displayed to the user in the administrative user interface. It is important that the identifer for a control-system support does not change after its first release because existing channels using the control-system support would otherwise become unusable. The name, on the other hand, is only used for informational purposes and can thus be changed at a later point in time without having any impact on existing channels.
The control-system support has to implement methods for creating a
channel (so that the corresponding process variables is monitored for
changes), writing single samples, and reading samples from a single
sample bucket.
Each control-system support uses at least one table for storing its
samples.
This table should be created when instantiating the implementation of
the ControlSystemSupport interface for
the first time.
For details about the methods that have to be implemented, please refer
to the
API reference.
Unless explicitly specified otherwise, all methods of a control-system
support are expected to not block.
Operations that may not be able to finish instantly (e.g. retrieving
data from the database) return a Future
that finishes asynchronously.
This design has been chosen to allow the parallel processing of many
channels without having to use a very high number of threads.
You might want to study the code of the
Channel Access control-system support
as an example of how such an implementation might work.
The Cassandra PV Archiver stores its data in several CQL tables, listed in Table A.1, “Cassandra PV Archiver CQL tables”.
| Table name | Description |
|---|---|
| cluster_servers | Status and location information for Cassandra PV Archiver servers |
| pending_channel_operations_by_server | Protective entries for channels in order to prevent concurrent modifications |
| channels | Channel configuration and information about sample buckets for each channel |
| channels_by_server | Channel configuration and state for all channels associated with each server (for faster startup) |
| generic_data_store | Generic configuration information (e.g. credentials for the administrative user interface) |
In addition to these tables, each control-system support has one ore more
tables.
Please refer to the documentation of the respective control-system support
for details.
Most of the tables listed earlier are considered internal to the operation
of the Cassandra PV Archiver and thus are not discussed in greater detail.
Only the channels table is relevant for accessing data
stored in the archive. This table is discussed in
Section 1, “Table channels”.
The channels table stores configuration information
and information about sample buckets for each channel.
The table’s structure is described by
Table A.2, “Columns of table channels”.
| Column name | Column type | Data type | Description |
|---|---|---|---|
| channel_name | Partition key | text | Channel name. |
| decimation_level | Clustering Key | int | Decimation level (identified by the decimation period in seconds). Zero indicates raw samples. |
| bucket_start_time | Clustering Key | bigint | Start time of the sample bucket (in nanoseconds since epoch, which is January 1st, 1970, 00:00:00 UTC). |
| bucket_end_time | Regular | bigint | End time of the sample bucket (in nanoseconds since epoch, which is January 1st, 1970, 00:00:00 UTC). |
| channel_data_id | Static | uuid | Data ID associated with the channel. This information is used to identify associated data in the control-system support’s table(s). |
| control_system_type | Static | text | ID of the control-system support used for the channel. |
| decimation_levels | Static | set<int> | Set containing all decimation levels that exist for the channel (identified by their decimation periods in seconds). |
| server_id | Static | uuid | UUID of the server to which the channel belongs. |
The channel name is used as the partition key and the decimation level and bucket start time are used as clustering keys. This means that for each channel, there is a partition and for each sample bucket there is a row in this partition. The ordering of the clustering keys (decimation level first, bucket start time second) makes it possible to search for sample buckets for a specific decimation level that are in a certain time range. All configuration information is stored in static columns (columns that are shared among all rows in the partition) because this information obviously does not depend on the sample bucket.
The bucket end time is a regular column and thus it is not possible to search by end time. However, the end time is typically just one nanosecond before the start time of the following bucket (it is guaranteed to be strictly less than the start time of the next bucket). Therefore, there is usually no need to search based on the end time.
When reading samples, one has to search for the sample buckets that store the samples for the relevant period of time. One can use a query like the following to search for all sample buckets that start in a certain period of time:
SELECT * FROM channels WHERE channel_name = 'myChannel' AND decimation_level = 0 AND bucket_start_time >= 1468429000000000000 AND bucket_start_time <= 1468431000000000000 ORDER BY decimation_level ASC;
In this example, myChannel is the name of the channel
and we search for sample buckets storing raw samples (decimation period of
0) and starting between the time stamps
1468429000000000000 and
1468431000000000000.
It might seem strange to order by the
decimation_level column when we actually want to
order by the bucket_start_time column.
However, Cassandra (currently) only allows specifying the first column
of a composite clustering key in the ORDER BY clause.
The ORDER BY clause still has the intended effect of
(also) ordering by the bucket_start_time column.
Typically, one also needs the sample bucket that starts before the lower time-stamp, unless there is a sample bucket starting right at the lower limit of the search period, which will only happen by chance. One can retrieve information about this sample bucket with a query like the following:
SELECT * FROM channels WHERE channel_name = 'myChannel' AND decimation_level = 0 AND bucket_start_time < 1468429000000000000 ORDER BY decimation_level DESC LIMIT 1;
We are only interested in the first sample bucket just before our lower limit, which is why we use descending order and limit the results to a single row.
Once we know the sample buckets, we can retrieve the corresponding
samples from the control-system support’s table(s).
We need the channel_data_id,
decimation_level, and
bucket_start_time in order to identify the sample
bucket in the control-system support’s table(s).
When querying these tables, the time stamp of the samples should be
limited to the range specified by the
bucket_start_time and
bucket_end_time, unless the limits imposed by the
time period that is queried are more narrow.
Always using these limits ensures that we do not read samples that have
accidentally been written into a sample bucket where they do not belong.
Usually, such samples should not exist, but it is better to be safe.
The JSON-based archive access protocol is the protocol that is used by the plugin for Control System Studio’s Data Browser. This protocol may also be used by other clients that want to retrieve data from the archive.
Unless the archive-access port has been changed, the base URL used for all
requests concerning the JSON-based archive-access protocol 1.0 is
http://myserver.example.com:9812/archive-acess/api/1.0.
This base has to be prepended to all URLs that are mentioned in this
protocol specification.
The host name myserver.example.com is just an example
and has to be replaced with the real hostname of a Cassandra PV Archiver
server.
The port 9812 is the default port used for the archive-access protocol and
only has to be changed if the archive access port has been changed in the
server’s configuration file.
All requests are made by specifying query parameters in the URL.
The request body is always empty.
The response is always sent in the JSON format (MIME type
application/json) unless there is an error (which is identified by a
corresponding HTTP status code).
All requests are sent as GET requests.
The Cassandra PV Archiver server supports deflate and gzip compression of the response body if support for compression is indicated by the client. For JSON data, compression can dramatically reduce the amount of data that has to be transferred, so clients should support compression when possible.
The request URL for retrieving the list of available archives has the following form:
/archive/[?prettyPrint]
If the optional prettyPrint parameter is present,
the output is formatted nicely, which can be useful for debugging.
Usually, this parameter should be omitted because this will result in
a more compact representation, saving bandwidth.
The response is a JSON array, each element being one available archive (JSON object). Each of these JSON objects has the following fields:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| key | int | number (must be in integer format) | numeric key identifying the archive (unique) |
| name | string | string | name of the archive (might not be unique) |
| description | string | string | description of the archive |
Originally, the JSON protocol was not designed for the Cassandra PV
Archiver, but as a general protocol for accessing archives.
For this reason, it supports servers that provide more than one
archive.
The Cassandra PV Archiver server only provides a single archive, so
simple clients can simply assume that the archive key is always
1.
The server still supports retriving the archive information so that it
is compatible with clients implementing the protocol completely and
thus supporting multiple archives.
The request URL used in order to search for channels takes one of the following two forms:
/archive/<archive key>/channels-by-pattern/<glob pattern expression>↪[?prettyPrint] /archive/<archive key>/channels-by-regexp/<regular expression>;[?prettyPrint]
The archive key is the numeric key of the
archive as specified in the list of archives (typically
1).
The search for a channel name can be done with a glob pattern or a regular expression. In either case, the pattern needs to be URL encoded so that all special characters (in particular those that have a special meaning in a URL, like the question mark) are encoded with %xx where xx is the hexadecimal character code. This includes the special wildcard characters that are part of the pattern. When the expression contains non-ASCII characters, those characters are expected to be specified in UTF-8 encoding.
When using a glob pattern, the channels-by-pattern
URL has to be used.
In the glob pattern expression, the ? and *
characters have a special meaning.
The question mark acts as wildcard that matches exactly one character.
The asterisk acts as a wildcard that matches an arbitrary number of
characters (including zero characters).
When using a regular expression, the
channels-by-regexp URL has to be used.
The regular expression must be specified in
a form that is understood by the
java.util.regex.Pattern.compile(java.lang.String)
method.
If the optional prettyPrint parameter is present,
the output is formatted nicely, which can be useful for debugging.
Usually, this parameter should be omitted because this will result in
a more compact representation, saving bandwidth.
The response is a JSON array, containing JSON strings, where each string is a channel name. When no matching channel is found, an empty array is returned.
The request URL for retrieving samples for a specific channel has the following form:
/archive/<archive key>/samples/<channel name>?start=<start time-stamp>& ↪end=<end time-stamp>[&count=<desired number of samples>][&prettyPrint]
The archive key is the numeric key of the
archive as specified in the list of archives (typically
1).
The channel name is the name of the channel
for which samples are requested.
The channel name must be URL encoded so that all special characters
(in particular those that have a special meaning in a URL, like the
question mark) are encoded with %xx where xx is the hexadecimal
character code.
When the channel name contains non-ASCII characters, those characters
are expected to be specified in UTF-8 encoding.
The start time-stamp specifies the start of
the interval for which samples are requested.
The time stamp is specified as the number of nanoseconds since epoch
(January 1st, 1970, 00:00:00 UTC).
The end time-stamp specifies the end of
the interval for which samples are requested.
The time stamp is specified as the number of nanoseconds since epoch
(January 1st, 1970, 00:00:00 UTC).
The count parameter is optional.
If specified, the desired number of samples
is a strictly positive number that specifies the number of samples
that should be returned.
The number of samples returned will usually not match this number
exactly.
However, if samples with various densities are available, the density
which will result in the number of samples closest to the requested
number is chosen.
If this parameter is not specified, raw samples are used.
If the optional prettyPrint parameter is present,
the output is formatted nicely, which can be useful for debugging.
Usually, this parameter should be omitted because this will result in
a more compact representation, saving bandwidth.
The response is a JSON array, each element being one sample (JSON object). In addition to the samples between the start and the end time-stamp, one sample at or before the start time-stamp and one sample at or after the end time-stamp is returned (if such samples exist at all). This way, the returned data is sufficient for creating a plot covering the whole interval, even if the specified time stamps do not exactly match the time stamps of samples.
Each of the sample objects can have the following fields:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| time | big integer | number (must be in integer format) | time-stamp in nanoseconds since epoch (January 1st, 1970, 00:00:00 UTC) |
| severity | see below | object | alarm severity |
| status | string | string | alarm status (might contain additional information about the severity) |
| quality | string | string | sample quality - one of “Original” or “Interpolated” (not case-sensitive) |
| metaData | see below | object | meta-data of the sample |
| type | string | string | sample type - must be one of “double”, “enum”, “long”, “minMaxDouble”, or “string” (not case-sensitive) |
| value | depends on sample type | array | array of values making up the sample |
| minimum | double | number or string | minimum value – must be in number format unless it cannot be expressed as a JSON number (e.g. infinity) |
| maximum | double | number or string | maximum value – must be in number format unless it cannot be expressed as a JSON number (e.g. infinity) |
The type, time,
severity, status,
quality, and value fields are
always present.
The minimum and maximum fields
are only present if the type is minMaxDouble.
The type field must always come before the
value field.
The quality field indicates whether the sample is a
raw sample (“Original”) or a decimated sample (“Interpolated”).
The metaData field may be present for all types
except the string type.
The format of the meta-data depends on the type (see below).
At places where a number may also be expressed as a JSON string, the
use of a string is reserved to cases where the number cannot be
represented as a JSON number (infinity and not-a-number).
Valid strings are inf, infinity,
+inf, +infinity,
-inf, -infinity, and
nan (all not case-sensitive).
The value is always represented as a JSON array. The type of the array elements depends on the sample type:
| Sample type | Element JSON type | Remarks |
|---|---|---|
| double | number or string | must be in number format unless it cannot be expressed as a JSON number (e.g. infinity) |
| enum | number | must be in integer format, numbers outside the interval [-231, 231-1] may be truncated |
| long | number | must be in integer format, numbers outside the interval [-263, 263-1] may be truncated |
| minMaxDouble | number or string | must be in number format unless it cannot be expressed as a JSON number (e.g. infinity) |
| string | string |
The minMaxDouble type is used for samples that have
been aggregates from several raw samples and the
minimum and maximum represent
the least and the greatest value of any of the original samples.
Sample of type minMaxDouble typically have a
quality of “Interpolated” because they represent
decimated samples.
The severity is a JSON object with the following fields (all mandatory):
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| level | string | string | sample severity - one of “OK”, “MINOR”, “MAJOR”, or “INVALID” (all not case-sensitive) |
| hasValue | boolean | boolean | tells whether the sample has a value (or just signals a condition with a certain severity) |
The meta-data is a JSON object.
The format depends on the sample type.
Samples that are of the string type do not have
meta data.
Samples that are of the enum type can have meta
data in the following format (all fields are mandatory):
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| type | string | string | value is always “enum” (not case-sensitive) |
| states | array of strings | array of strings | labels for the enum states |
Samples that are of the double,
long, or minMaxDouble type can
have meta data in the following format (all fields are mandatory):
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| type | string | string | value is always “numeric” (not case-sensitive) |
| precision | integer | number | number of fractional digits to be displayed, must be in integer format |
| unit | string | string | engineering units of the value |
| displayLow | double | number or string | lower display limit – must be in number format unless it cannot be expressed as a JSON number (e.g. infinity) |
| displayHigh | double | number or string | upper display limit – must be in number format unless it cannot be expressed as a JSON number (e.g. infinity) |
| warnLow | double | number or string | lower warning limit – must be in number format unless it cannot be expressed as a JSON number (e.g. infinity) |
| warnHigh | double | number or string | upper warning limit – must be in number format unless it cannot be expressed as a JSON number (e.g. infinity) |
| alarmLow | double | number or string | lower alarm limit – must be in number format unless it cannot be expressed as a JSON number (e.g. infinity) |
| alarmHigh | double | number or string | upper alarm limit – must be in number format unless it cannot be expressed as a JSON number (e.g. infinity) |
Request:
GET /archive-access/api/1.0/archive/1/samples/testCalc?start=0& ↪end=1500000000000000000&prettyPrint HTTP/1.0
Response:
[ {
"time" : 1468429059824011000,
"severity" : {
"level" : "OK",
"hasValue" : true
},
"status" : "NO_ALARM",
"quality" : "Original",
"metaData" : {
"type" : "numeric",
"precision" : 2,
"units" : "V",
"displayLow" : 0.0,
"displayHigh" : 0.0,
"warnLow" : "NaN",
"warnHigh" : 12.0,
"alarmLow" : "NaN",
"alarmHigh" : 15.0
},
"type" : "double",
"value" : [ 7.0 ]
}, {
"time" : 1468429060825564000,
"severity" : {
"level" : "MINOR",
"hasValue" : true
},
"status" : "HIGH",
"quality" : "Original",
"metaData" : {
"type" : "numeric",
"precision" : 2,
"units" : "V",
"displayLow" : 0.0,
"displayHigh" : 0.0,
"warnLow" : "NaN",
"warnHigh" : 12.0,
"alarmLow" : "NaN",
"alarmHigh" : 15.0
},
"type" : "double",
"value" : [ 12.0 ]
} ]
The JSON-based administrative web-service API can be used to monitor and configure the Cassandra PV Archiver server. It offers most of the functions available through the administrative user interface, but is designed to be used by other software (e.g. scripts used for automating the configuration management).
The base URL used for all requests concerning this API is:
http://<server>:<port>/admin/api/<version number>
In this URL <server> is the hostname or
IP address of the archive server,
<port> is the TCP port number of the
administrative interface, and
<version number> is the protocol
version.
At the moment, the only protocol version supported by the server is 1.0.
This base has to be prepended to all URLs that are mentioned in this
protocol specification.
If not configured explicitly in the server configuration, the
administrative interface is made available on port 4812.
The API uses JSON for both request and response bodies.
Requests only reading data typically use the GET
method and have an empty request body.
If there are any parameters, they are passed as part of the URL (in the
path or query string).
When passing parameters as part of the path (not the query string), they
have to be encoded in a non-standard way (see
the section called “Encoding URI components” for details).
Read requests do not require authentication.
Requests making modification typically use the POST
method (unless specified differently).
Such requests typically expect parameters in the request’s body.
For some requests however, some of the parameters might still have to
be specified as part of the URL.
Requests making modifications must be accompanied by an
Authorization HTTP header for HTTP basic
authentication.
Invalid credentials result may result in a response with status 403
(forbidden), even if the requested resource does actually not require
authentication.
For this reason, requests to resources not requiring authentication
should rather be made without an Authorization
header than a header containing invalid credentials.
Invalid request parameters (e.g. a request body that does not adhere to the format specified for the respective function) may result in a response with status 400 (bad request).
The response is always sent in the JSON format (MIME type
application/json) unless there is an error (which
is identified by a corresponding HTTP status code).
The request body (if present) also has to be sent in the JSON format
(MIME type application/json).
Unless specified differently, numbers are always serialized as JSON strings for three reasons: First, JSON numbers cannot be used as keys in maps (attribute names in JSON objects). Second, certain special numbers (e.g. positive and negative infinity) cannot be specified as JSON numbers. Third, many JSON parsers convert all numbers to 64-bit floating point values, resulting in precision loss for large integers.
As a general rule, when the member of a JSON object may have a value
of null, it may also be missing.
A missing member must always be interpreted in the same way as the
respective member having a null value.
Parameters that are passed as part of the query string use regular URI encoding (as specified by RFC 3986). Parameters that are passed as part of the path use a slightly different encoding that is specified in this section.
In order to encode a parameter value, it is first serialized as UTF-8. In the resulting byte sequence, each byte that does not represent one of the ASCII characters “A” to “Z”, “a” to “z”, “0” to “9”, “-” (minus), or “_” (underscore) is escaped by a three byte sequence in the form “~” (tilde), hex digit, hex digit. The two hex digits are the escaped byte’s value in hexadecimal representation. The hex digits “A” to “F” should be represented in upper case.
For example, the string “some test” is encoded as “some~20test”. The string “allowed_characters_only” stays the same. The string “a/b” is encoded as “a~2Fb”. The string “süper” is encoded as “s~C3~BCper”.
The request URL for retrieving the list of all channels has the following form:
/channels/all/
The request must use the GET method.
The response is a JSON object with the channels
attribute as its only member.
The channels attribute has an array as its value
that contains an element for each channel.
Each of these elements is an object with the following attributes:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| channelDataId | UUID | string | internal ID for the channel |
| channelName | string | string | channel’s name |
| controlSystemName | string | string | human-readable name of the control-system support used for the channel |
| controlSystemType | string | string | internal identifier for the control-system support used for the channel |
| decimationLevels | set of int | array of string | decimation levels that exist for the channel (specified in seconds) |
| serverId | UUID | string | ID of the server that owns the channel |
| serverName | string | string | human-readable name of the server that owns the channel |
If the list of channels is currently not available, HTTP error code 503 (service unavailable) is returned and the response body is invalid.
Request:
GET /admin/api/1.0/channels/all/
Response:
{
"channels": [
{
"channelDataId": "ef126a63-375b-4f28-a1d1-17e8f42271a9",
"channelName": "someChannel",
"controlSystemName": "Channel Access",
"controlSystemType": "channel_access",
"decimationLevels": ["0", "30", "900"],
"serverId": "7cf8f393-cd00-46ae-9343-53e9cb5793fd",
"serverName": "myserver"
},
{
"channelDataId": "0993955f-d16e-486d-ac3b-6a1841c0fd3f",
"channelName": "someOtherChannel",
"controlSystemName": "Channel Access",
"controlSystemType": "channel_access",
"decimationLevels": ["0"],
"serverId": "7cf8f393-cd00-46ae-9343-53e9cb5793fd",
"serverName": "myserver"
}
]
}
The request URL for retrieving the list of channels for a server has the following form:
/channels/by-server/<server ID>/
The <server ID> has to be replaced by
the UUID associated with the respective server.
The request must use the GET method.
The response is a JSON object with the channels and
statusAvailable attributes as its members.
The statusAvailable attribute is a boolean
indicating whether the list of channels includes status information
(true) or only configuration information
(false).
Status information is only available if the specified server is
online.
The channels attribute has an array as its value
that contains an element for each channel.
Each of these elements is an object with the following attributes:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| channelDataId | UUID | string | internal ID for the channel |
| channelName | string | string | channel’s name |
| controlSystemName | string | string | human-readable name of the control-system support used for the channel |
| controlSystemType | string | string | internal identifier for the control-system support used for the channel |
| decimationLevelToRetentionPeriod | map of int to int | object with string attribute values | decimation levels that exist for the channel and their respective retention periods (both specified in seconds) |
| enabled | boolean | boolean |
true if the channel is enabled,
false if it is disabled.
|
| errorMessage | string | string |
error message for the channel. May be null.
|
| options | map of string to string | object with string attribute values | control-system-specific configuration options that have been specified for the channel (the attribute name is the option name and the attribute value is the option value) |
| state | string | string |
channel’s current state. One of destroyed,
disabled, disconnected,
error, initializing,
or ok.
null if status information is not
available.
|
| totalSamplesDropped | long | string |
number of samples that have been dropped for the channel
(since the last reinitialization).
null if status information is not
available.
|
| totalSamplesSkippedBack | long | string |
number of samples that were discarded because they skipped
back in time (since the last reinitialization).
null if status information is not
available.
|
| totalSamplesWritten | long | string |
number of samples that have been written for the channel
(since the last reinitialization).
null if status information is not
available.
|
If the list of channels is currently not available, HTTP error code 503 (service unavailable) is returned and the response body is invalid. If the specified server does not exist, HTTP error code 404 (not found) is returned and the response body is invalid.
Request:
GET /admin/api/1.0/channels/by-server/7cf8f393-cd00-46ae-9343-53e9cb5793fd/
Response:
{
"channels": [
{
"channelDataId": "ef126a63-375b-4f28-a1d1-17e8f42271a9",
"channelName": "someChannel",
"controlSystemName": "Channel Access",
"controlSystemType": "channel_access",
"decimationLevelToRetentionPeriod": {
"0": "864000",
"30": "31536000",
"900": "0"
},
"enabled": true,
"errorMessage": null,
"options": {},
"state": "OK",
"totalSamplesDropped": "0",
"totalSamplesSkippedBack": "1",
"totalSamplesWritten": "42"
},
{
"channelDataId": "0993955f-d16e-486d-ac3b-6a1841c0fd3f",
"channelName": "someOtherChannel",
"controlSystemName": "Channel Access",
"controlSystemType": "channel_access",
"decimationLevelToRetentionPeriod": {"0": "0"},
"enabled": true,
"errorMessage": "Invalid control-system option \"noSuchOption\".",
"options": {
"noSuchOption": "some value"
},
"state": "ERROR",
"totalSamplesDropped": "0",
"totalSamplesSkippedBack": "0",
"totalSamplesWritten": "0"
}
],
statusAvailable: true
}
The request URL for retrieving information about a single channel has the following form:
/channels/all/by-name/<channel-name>//channels/by-server/<server ID>/by-name/<channel-name>/
Both variants return the same data.
The only difference between them is that the variant that includes the
server ID in the URL will return status code 404 (not found) when the
channel exists, but belongs to a different server.
The <channel name> has to be replaced
by the encoded form of the channel name.
The <server ID> has to be replaced by
the UUID associated with the respective server.
Only use the second variant if the query shall be limited to a
specific server.
The request must use the GET method.
The response is a JSON object with the following attributes:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| channelDataId | UUID | string | internal ID for the channel |
| channelName | string | string | channel’s name |
| controlSystemName | string | string | human-readable name of the control-system support used for the channel |
| controlSystemType | string | string | internal identifier for the control-system support used for the channel |
| decimationLevelToRetentionPeriod | map of int to int | object with string attribute values | decimation levels that exist for the channel and their respective retention periods (both specified in seconds) |
| enabled | boolean | boolean |
true if the channel is enabled,
false if it is disabled.
|
| errorMessage | string | string |
error message for the channel. May be null.
|
| options | map of string to string | object with string attribute values | control-system-specific configuration options that have been specified for the channel (the attribute name is the option name and the attribute value is the option value) |
| serverId | UUID | string | ID of the server that owns the channel |
| serverName | string | string | human-readable name of the server that owns the channel |
| state | string | string |
channel’s current state. One of destroyed,
disabled, disconnected,
error, initializing,
or ok.
null if status information is not
available.
|
| totalSamplesDropped | long | string |
number of samples that have been dropped for the channel
(since the last reinitialization).
null if status information is not
available.
|
| totalSamplesSkippedBack | long | string |
number of samples that were discarded because they skipped
back in time (since the last reinitialization).
null if status information is not
available.
|
| totalSamplesWritten | long | string |
number of samples that have been written for the channel
(since the last reinitialization).
null if status information is not
available.
|
If information about the channel can currently not be retrieved, HTTP error code 503 (service unavailable) is returned and the response body is invalid. If the channel does not exist or if a server ID has been specified and the channel belongs to a different server, HTTP error code 404 (not found) is returned and the response body is invalid.
Request:
GET /admin/api/1.0/channels/all/by-name/someChannel/
Response:
{
"channelDataId": "ef126a63-375b-4f28-a1d1-17e8f42271a9",
"channelName": "someChannel",
"controlSystemName": "Channel Access",
"controlSystemType": "channel_access",
"decimationLevelToRetentionPeriod": {
"0": "864000",
"30": "31536000",
"900": "0"
},
"enabled": true,
"errorMessage": null,
"options": {},
"serverId": "7cf8f393-cd00-46ae-9343-53e9cb5793fd",
"serverName": "myserver",
"state": "OK",
"totalSamplesDropped": "0",
"totalSamplesSkippedBack": "1",
"totalSamplesWritten": "42"
}
The request URL for importing the channel configuration for a server has the following form:
/channels/by-server/<server ID>/import
The <server ID> has to be replaced by
the UUID associated with the respective server.
The request must use the POST method.
The request body must be a JSON object with the following members:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| addChannels | boolean | boolean |
true if channels present in the
configuration file, but missing on the server shall be added
to the server.
false if no new channels shall be added to
the server.
Default is false.
|
| configurationFile | array of byte | string | Base64 (RFC 4648) encoded contents of the configuration file that shall be imported. |
| removeChannels | boolean | boolean |
true if channels missing in the
configuration file, but present on the server shall be removed
from the server.
false if no new channels shall be removed
from the server.
Default is false.
|
| simulate | boolean | boolean |
true if no modifications shall be made.
This means that the response will have the same content as if
all changes where applied successfully.
This is useful in combination with the
removeChannels option in order to see which
channels would be removed.
Default is false.
|
| updateChannels | boolean | boolean |
true if channels present in the
configuration file and also present on the server shall be
updated to match the configuration specified in the file.
false if no existing channels shall be
changed.
Default is false.
|
The response is a JSON object with the with the following members:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| addOrUpdateFailed | map of string to string | object (with string attribute values) |
object with a member for each channels for which an add or
update operation failed.
The channel name is the member’s key and the corresponding
error message is the member’s value.
May be null if there is a global error or
if the data is sent in response to a request that has the
simulate flag set.
|
| addOrUpdateSucceeded | set of string | array of string |
list of channels for which an add or update operation was
successful.
In case of an update operation, this does not necessarily mean
that the server configuration has been updated.
It might also have already been identical to the configuration
specified by the file.
May be null if there is a global error.
|
| errorMessage | string | string |
error message indicating a global problem.
Such a problem does not affect a specific channel, but the
import process in general (e.g. a syntax error in the
configuration file).
If such an error is present, no changes have been made to the
server configuration.
null if there is no global error.
|
| removeFailed | map of string to string | object (with string attribute values) |
object with a member for each channel for which a remove
operation failed.
The channel name is the member’s key and the corresponding
error message is the member’s value.
May be null if there is a global error or
if the data is sent in response to a request that has the
simulate flag set.
|
| removeSucceeded | set of string | array of string |
list of channels for which a remove operation was successful.
May be null if there is a global error.
|
If there is a problem with the request parameters (e.g. a syntax eror
in the configuration file), HTTP error code 400 (bad request) is
returned.
If there is a general problem with the request body, the response body
is invalid.
If there only is a problem with the contents of the configuration
file, a valid JSON response with the errorMessage
set is returned.
If the user could not be authenticated or is not authorized to use
the import function, HTTP error code 403 (forbidden) is returned and
the response body is invalid.
If there is an error when applying the changes for at least one
channel, HTTP error code 500 (internal server error) is returned and
the channel is added to the addOrUpdateFailed or
removeFailed maps.
If there is a general problem while processing the request (e.g. the
database is currently unavailable), HTTP error code 503 (service
unavailable) is returned and the errorMessage is
set in the response.
Request:
POST /admin/api/1.0/channels/by-server/7cf8f393-cd00-46ae-9343-53e9cb5793fd/import
{
"addChannels": true,
"configurationFile": "PD94bWwgdmVy... (shortened for this example)",
"removeChannels": true
}
Response:
{
"addOrUpdateFailed": {
"someChannel": "Channel \"someChannel\" cannot be added because a channel
↪with the same name already exists."
},
"addOrUpdateSucceed": [
"newChannel"
],
"errorMessage": null,
"removeFailed": {},
"removeSucceeded": [
"someOtherChannel"
]
}
The request URL for exporting the channel configuration for a server has the following form:
/channels/by-server/<server ID>/export
The <server ID> has to be replaced by
the UUID associated with the respective server.
The request must use the GET method.
The response is a JSON object with the with the following members:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| configurationFile | array of byte | string | Base64 (RFC 4648) encoded contents of the exported configuration file |
If there is a general problem while processing the request (e.g. the
database is currently unavailable), HTTP error code 503 (service
unavailable) is returned and the errorMessage is
set in the response.
If the specified server does not exist, HTTP error code 404 (not
found) is returned and the response body is invalid.
The request URL for running archive configuration commands has the following form:
/run-archive-configuration-commands
The request must use the POST method.
The request body must be a JSON object that has a single member.
This member has the key commands and an array as
its value.
Each of the array elements must be a JSON object that represents an
archive configuration command.
The format of the object depends on the respective command and is described in the section called “Archive Configuration Commands”. Commands may be processed in parallel, so a single request should never specify more than one command that affects the same channel as the result is not predictable.
The response is a JSON object with the with the following members:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| errorMessage | string | string |
error message indicating a global problem.
Such a problem does not affect a specific channel, but the
whole execution (e.g. problems while accessing the database).
If such an error is present, no changes have been made to the
server configuration.
null if there is no global error.
|
| results | array of object | array of object |
result object for each command that was specified in the
request.
The results have the same order as the commands had in the
request.
May be null if
errorMessage is set.
|
Each result object is a JSON object with the following structure:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| command | object | object | command to which this result belongs. This command object is equal to the one that has been specified in the request, but some members may differ slightly due to normalization. |
| errorMessage | string | string |
error message describing the reason for which the operation
failed.
null if the operation was successful or if
no explanation for the error is available.
|
| success | boolean | boolean |
true if the command was executed
successfully, false if the command failed.
|
If the user could not be authenticated or is not authorized to use
the import function, HTTP error code 403 (forbidden) is returned and
the response body is invalid.
If there is an error for at least one command, HTTP error code 500
(internal server error) is returned and the success
member of the corresponding command or commands is set to
false.
If there is a general problem while processing the request (e.g. the
database is currently unavailable), HTTP error code 503 (service
unavailable) is returned and the errorMessage is
set in the response.
There are seven different archive configuration commands:
- add channel
- add or update channel
- move channel
- refresh channel
- remove channel
- rename channel
- update channel
Each command is described by a JSON object, but except for the common
commandType member, each of the different commands
has a slightly different structure.
Add channel
The add channel command adds a new channel to the archive configuration. The channel is only added if it does not exist yet. If there already is a channel with the same name, the operation fails. The object for the add channel command has the following structure:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| channelName | string | string | name of the channel that shall be added. |
| commandType | enum | string |
always the literal string add_channel.
|
| controlSystemType | string | string | internal identifier for the control-system support that shall be used for the channel. This is the same identifier that is also used in configuration files. |
| decimationLevels | set of int | array of string |
decimation levels for the channel (identified by their
decimation periods specified in seconds).
The raw decimation level (with a decimation period of zero) is
always added, even if it is not specified in the array.
If the whole array is null, this is
interpreted like an array containing zero as its only element.
|
| decimationLevelToRetentionPeriod | map of int to int | object with string member values |
retention period for each decimation level (specified in
seconds).
Each member uses the decimation period of the respective
decimation level as its key and the retention period as its
value.
A value of zero means that samples shall be retained
indefinitely.
Entries for a decimation level that is not also specified in
decimationLevels are discarded (except for
the raw decimation level which is always included implicitly).
Negative retention periods are converted to zero.
If a decimation level is specified in
decimationLevels, but not in
decimationLevelToRetentionPeriod, a
retention period of zero is assumed.
If the whole object is null, a retention
period of zero is used for all decimation levels.
|
| enabled | boolean | boolean |
true if archiving shall be enabled for the
channel, false if archiving shall be
disabled.
|
| options | map of string to string | object with string member values |
control-system-specific configuration options.
The member key is the option name and the member value is the
option value.
Specifying null has the same effect as
specifying an empty object.
|
| serverId | UUID | string | UUID of the server to which the channel shall be added. |
Add or update channel
The add or update channel command is very similar to the add channel command. However, instead of failing when the specified channel already exists, it updates the channel configuration to match the specified configuration.
The control-system type of a channel cannot be changed, so the command fails if the channel exists, but its control-system type does not match the specified control-system type. The command also fails when the specified server ID does not match the server ID of the already existing channel. Channels can be moved from one server to another one, but the move channel command has to be used for this task.
The object for the add or update channel command has the same
structure as the add channel command, only the value of the
commandType member is different:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| channelName | string | string | name of the channel that shall be added or updated. |
| commandType | enum | string |
always the literal string
add_or_update_channel.
|
| controlSystemType | string | string | internal identifier for the control-system support that shall be used for the channel. This is the same identifier that is also used in configuration files. |
| decimationLevels | set of int | array of string |
decimation levels for the channel (identified by their
decimation periods specified in seconds).
The raw decimation level (with a decimation period of zero) is
always added, even if it is not specified in the array.
If the whole array is null, this is
interpreted like an array containing zero as its only element.
|
| decimationLevelToRetentionPeriod | map of int to int | object with string member values |
retention period for each decimation level (specified in
seconds).
Each member uses the decimation period of the respective
decimation level as its key and the retention period as its
value.
A value of zero means that samples shall be retained
indefinitely.
Entries for a decimation level that is not also specified in
decimationLevels are discarded (except for
the raw decimation level which is always included implicitly).
Negative retention periods are converted to zero.
If a decimation level is specified in
decimationLevels, but not in
decimationLevelToRetentionPeriod, a
retention period of zero is assumed.
If the whole object is null, a retention
period of zero is used for all decimation levels.
|
| enabled | boolean | boolean |
true if archiving shall be enabled for the
channel, false if archiving shall be
disabled.
|
| options | map of string to string | object with string member values |
control-system-specific configuration options.
The member key is the option name and the member value is the
option value.
Specifying null has the same effect as
specifying an empty object.
|
| serverId | UUID | string | UUID of the server to which the channel shall be added if it does not exist yet or to which it must belong if it already exists. |
Move channel
The move channel command moves a channel from one server to a
another one.
If the specified channel does not exist, the command fails.
It also fails if the specified expectedOldServerId
does not match the server ID of the channel’s current server.
The object for the move channel command has the following structure:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| channelName | string | string | name of the channel that shall be moved. |
| commandType | enum | string |
always the literal string move_channel.
|
| expectedOldServerId | UUID | string |
expected UUID of the server which currently owns the channel.
If null, the channel is moved regardless of
the server it currently belongs to.
|
| newServerId | UUID | string | UUID of the server to which the channel shall be moved. |
Refresh channel
The refresh channel command causes a server to temporarily stop archiving for that channel, reload its configuration, and resume archiving with the freshly loaded configuration. This command succeeds, even if the channel does not exist or actually exists on a different server. However, the actual refresh action only happens on the specified server. The object for the refresh channel command has the following structure:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| channelName | string | string | name of the channel that shall be refreshed. |
| commandType | enum | string |
always the literal string refresh_channel.
|
| serverId | UUID | string | UUID of the server on which the refresh action should run. This does not have to be, but typically should be the UUID of the server that owns the channel. |
Remove channel
The remove channel command deletes a channel (and all its data).
If the specified channel does not exist, the command fails.
It also fails if the specified expectedServerId
does not match the server ID of the channel’s current server.
The object for the remove channel command has the following structure:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| channelName | string | string | name of the channel that shall be deleted. |
| commandType | enum | string |
always the literal string remove_channel.
|
| expectedServerId | UUID | string |
expected UUID of the server which currently owns the channel.
If null, the channel is deleted regardless
of the server it currently belongs to.
|
Rename channel
The rename channel command changes the name of a channel.
If the specified channel does not exist or the specified
newChannelName is already in use, the command
fails.
It also fails if the specified expectedServerId
does not match the server ID of the channel’s current server.
The object for the rename channel command has the following structure:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| commandType | enum | string |
always the literal string rename_channel.
|
| expectedServerId | UUID | string |
expected UUID of the server which currently owns the channel.
If null, the channel is renamed regardless
of the server it currently belongs to.
|
| newChannelName | string | string | new name for the channel. |
| oldChannelName | string | string | old name of the channel. |
Update channel
The update channel command updates the configuration of an existing
channel. If the specified channel does not exist, the operation fails.
It also fails if the expectedControlSystemType does
not match the actual control-system type of the channel or the
expectedServerId does not match the ID of the
server that owns the channel.
The set of decimation levels that shall be added and removed can be
described in an explicit or in a differential fashion.
For an explicit description, use the
decimationLevels member.
For a differential description, use the
addDecimationLevels and
removeDecimationLevels members.
Only one of the two ways to describe the change can be used at the
same time.
Setting both decimationLevels and either or both of
addDecimationLevels and
removeDecimationLevels results in an error.
If decimation levels are listed in decimationLevels
or addDecimationLevels, but do not have a
corresponding entry in
decimationLevelToRetentionPeriod, a retention
period of zero is assumed for these decimation levels, even if they
already exist with a different retention period.
Like the decimation levels, the control-system-specific configuration
options can also be described in an explicit or in a differential
fashion.
For an explicit description, use the options
member.
For a differential description, use the addOptions
and removeOptions members.
Only one of the two ways to describe the change can be used at the
same time.
Setting both options and either or both of
addOptions and removeOptions
results in an error.
The object for the update channel command has the following structure:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| addDecimationLevels | set of int | array of string |
decimation levels (identified by their decimation periods
specified in seconds) that shall be added for the channel.
If the whole array is null and
decimationLevels is also
null, no decimation levels are added.
|
| addOptions | map of string to string | object with string member values |
control-system-specific configuration options that shall be
added to the channel configuration.
The member key is the option name and the member value is the
option value.
If one of the specified options already exists, its value is
updated with the specified value.
If this member is null and
options is also null,
no control-system-specific options are added for the channel.
|
| channelName | string | string | name of the channel that shall be updated. |
| commandType | enum | string |
always the literal string
update_channel.
|
| decimationLevels | set of int | array of string |
decimation levels for the channel (identified by their
decimation periods specified in seconds).
The raw decimation level (with a decimation period of zero) is
always added, even if it is not specified in the array.
If the whole array is null and
addDecimationLevels and
removeDecimationLevels are also
null, no decimation levels are added or
removed.
If the array is not null all existing
decimation levels (except for the special raw decimation
level) that are not also specified in the array are removed.
|
| decimationLevelToRetentionPeriod | map of int to int | object with string member values |
retention period for each decimation level (specified in
seconds).
Each member uses the decimation period of the respective
decimation level as its key and the retention period as its
value.
A value of zero means that samples shall be retained
indefinitely.
Entries for a decimation level that are not also specified in
decimationLevels or
addDecimationLevels and that do not already
exist, are discarded (except for the raw decimation level
which is always included implicitly).
Negative retention periods are converted to zero.
If a decimation level is specified in
decimationLevels or
addDecimationLevels, but not in
decimationLevelToRetentionPeriod, a
retention period of zero is assumed.
If the whole object is null, a retention
period of zero is used for all decimation levels that are
newly added and the retention periods of all other decimation
levels are not changed.
|
| enabled | boolean | boolean |
true if archiving shall be enabled for the
channel, false if archiving shall be
disabled.
If null, the enabled flag is not changed.
|
| expectedControlSystemType | string | string |
internal identifier for the control-system support that is
expected to be used for the channel.
If null, the channel is updated regardless
of its control-system type.
|
| expectedServerId | UUID | string |
UUID of the server to which the channel must belong.
If null, the channel is updated regardless
of the server to which it belongs.
|
| options | map of string to string | object with string member values |
control-system-specific configuration options.
The member key is the option name and the member value is the
option value.
If this member is not null, all options
are replaced by the specified options, removing options that
existed before, but were not specified.
If this member is null and both
addOptions and
removeOptions are also
null, the control-system specific options
for the channel are not changed.
|
| removeDecimationLevels | set of int | array of string |
decimation levels (identified by their decimation periods
specified in seconds) that shall be removed from the channel.
If the whole array is null and
decimationLevels is also
null, no decimation levels are removed.
The special decimation level for raw samples is never removed,
even if zero is an element of this array.
|
| removeOptions | set of string | array of string |
control-system-specific configuration options (identified by
their names) that shall be removed from the channel
configuration.
If one of the specified options does not exist, it simply is
not removed.
If this member is null and
options is also null,
no control-system-specific options are removed from the
channel configuration.
|
Request:
POST /admin/api/1.0/run-archive-configuration-commands
{
"commands": [
{
"channelName": "someExistingChannel",
"commandType": "add_channel",
"controlSystemType": "channel_access",
"decimationLevels": ["0", "30", "300"],
"decimationLevelToRetentionPeriod": {
"0": "864000"
},
"enabled": true,
"serverId": "7cf8f393-cd00-46ae-9343-53e9cb5793fd"
},
{
"channelName": "someNewChannel",
"commandType": "add_channel",
"controlSystemType": "channel_access",
"decimationLevelToRetentionPeriod": {
"0": "31536000"
},
"enabled": true,
"options": {
"someControlSystemOption": "someValue"
},
"serverId": "7cf8f393-cd00-46ae-9343-53e9cb5793fd"
},
{
"addDecimationLevels": ["30"],
"channelName": "someOtherChannel",
"commandType": "update_channel",
"decimationLevelToRetentionPeriod": {
"0": "864000",
"30": "31536000"
}
}
]
}
Response:
{
"results": [
{
"command": {
"channelName": "someExistingChannel",
"commandType": "add_channel",
"controlSystemType": "channel_access",
"decimationLevels": ["0", "30", "300"],
"decimationLevelToRetentionPeriod": {
"0": "864000",
"30": "0",
"300": "0"
},
"enabled": true,
"serverId": "7cf8f393-cd00-46ae-9343-53e9cb5793fd"
},
"errorMessage": "Channel \"someExistingChannel\" cannot be added because a
↪channel with the same name already exists.",
"success": false
},
{
"command": {
"channelName": "someNewChannel",
"commandType": "add_channel",
"controlSystemType": "channel_access",
"decimationLevels": ["0"],
"decimationLevelToRetentionPeriod": {
"0": "31536000"
},
"enabled": true,
"options": {
"someControlSystemOption": "someValue"
},
"serverId": "7cf8f393-cd00-46ae-9343-53e9cb5793fd"
},
"success": true
},
{
"command": {
"addDecimationLevels": ["30"],
"channelName": "someOtherChannel",
"commandType": "update_channel",
"decimationLevelToRetentionPeriod": {
"0": "864000",
"30": "31536000"
}
},
"success": true
}
]
}
The request URL for retrieving the cluster status has the following form:
/cluster-status/
The request must use the GET method.
The response is a JSON object with the servers
attribute as its only member.
The servers attribute has an array as its value
that contains an element for each server in the cluster.
Each of these elements is an object with the following attributes:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| lastOnlineTime | long | string | last time the server successfully registered itself with the cluster. The time is specified as the number of milliseconds since January 1st, 1970, 00:00:00 UTC. |
| online | boolean | boolean | flag indicating whether the server is considered online. The server is considered online when it has recently renewed its registration. |
| serverId | UUID | string | ID of the server. |
| serverName | string | string | human-readable name of the server. Typically, this is the hostname of the server. |
If the cluster status is currently not available, HTTP error code 503 (service unavailable) is returned and the response body is invalid.
Request:
GET /cluster-status/
Response:
{
"servers": [
{
"lastOnlineTime": "1490634430220",
"online": true,
"serverId": "7cf8f393-cd00-46ae-9343-53e9cb5793fd",
"serverName": "myserver"
},
{
"lastOnlineTime": "1490634432760",
"online": true,
"serverId": "6fc4efe0-ea4a-438e-9b0a-b5e5654cbed9",
"serverName": "otherserver"
},
{
"lastOnlineTime": "1490631012050",
"online": false,
"serverId": "8c6959e2-0388-4854-8ebf-88a752375962",
"serverName": "thirdserver"
}
]
}
This function provides status information about the targeted server. In contrast to most other functions, it actually matters which server is used when running this command because the result will actually depend on the targeted server. The request URL has the following form:
/server-status/this-server/
The request must use the GET method.
The response is a JSON object with the following attributes:
| Field name | Internal data type | JSON data type | Description |
|---|---|---|---|
| cassandraClusterName | string | string |
human-readable name of the Cassandra cluster to which this
server is connected. May be null if the
server has not connected to the Cassandra cluster yet. In this
case, cassandraError is not
null.
|
| cassandraError | string | string |
error message indicating a problem that occurred while trying
to connect to the Cassandra cluster. This is
null if the connection to the Cassandra
cluster has been established after starting the server (even
if the connection is currently disrupted).
|
| cassandraKeyspaceName | string | string |
name of the Cassandra keyspace which is used by the Cassandra
PV Archiver. May be null if the server has
not connected to the Cassandra cluster yet. In this case,
cassandraError is not
null.
|
| channelsDisconnected | int | string | number of channels that are in the disconnected state. |
| channelsError | int | string | number of channels that are in the error state. |
| channelsTotal | int | string | total number of channels on this server. If the server has not been initialized yet (e.g. because it cannot connect to the database), this number is zero, even if there are channels that belong to the server. |
| serverId | UUID | string | ID of the server. |
| serverLastOnlineTime | long | string | last time this server successfully registered itself with the cluster. The time is specified as the number of milliseconds since January 1st, 1970, 00:00:00 UTC. This number might be zero if the server has not successfully registered itself with the cluster since it was started. |
| serverName | string | string | human-readable name of the server. Typically, this is the hostname of the server. |
| serverOnline | boolean | boolean | flag indicating whether the server considers itself to be online. The server considers itself online when a sufficient amount of time has passed since successfully registering with the cluster and the renewal of the registration has not failed since. |
| totalSamplesDropped | long | string | total number of samples that have been dropped (discarded) by this server because they arrived to quickly and could not be written in time. This counter is reset when the server is restarted. |
| totalSamplesWritten | long | string | total number of samples that have been written (persisted) by this server. This counter is reset when the server is restarted. |
Request:
GET /admin/api/1.0/server-status/this-server/
Response:
{
"cassandraClusterName": "My Cassandra cluster",
"cassandraError": null,
"cassandraKeyspaceName": "pv_archive",
"channelsDisconnected": "1",
"channelsError": "0",
"channelsTotal": "2",
"serverId": "7cf8f393-cd00-46ae-9343-53e9cb5793fd",
"serverLastOnlineTime": "1490634430220",
"serverName": "myserver",
"serverOnline": "true",
"totalSamplesDropped": "3",
"totalSamplesWritten": "4242"
}
The Channel Access control-system support is bundled with the standard
distribution of the Cassandra PV Archiver server.
It provides support for process variables that can be accessed through the
Channel Access protocol, which is the protocol typically used by
control systems that are based on
EPICS.
The Channel Access control-system support is identified by the ID
channel_access.
This control-system support is based on the EPICS Jackie library, which is internally used for implementing the Channel Access protocol. This way, the control-system support works on all platforms without having dependencies on any platform-specific libraries.
This appendix describes how the control-system support is configured (see Section 1, “Configuration”), how the sample decimation is implemented (see Section 2, “Decimated samples”), and how it stores samples in the database (see Section 3, “CQL table layout”).
The Channel Access control-system support offers a number of configuration options that can be specified for each channel. The same options can also be specified in the server’s configuration file (see Chapter III, Cassandra PV Archiver server, Section 3, “Server configuration”). When specified in the server’s configuration file, the options serve as defaults that are used when an option is not specified for a specific channel that is managed by the respective server.
When specified in the server’s configuration file, the options must be
specified in the controlSystem →
channelAccess section of the file or the prefix
controlSystem.channelAccess must be added to the
option name.
When specified for a channel, the option names are used without any
prefix being added.
Option names are case-sensitive.
The clockSource option specifies which time stamp
is used when archiving samples.
When set to local, the time of the archiving
server’s system clock is used.
When set to origin, the time that is sent by the
Channel Access server (together with the sample’s value) is used and
the
maxClockSkew option
controls when a sample is discarded without being archived.
When set to prefer_origin (the default), the
original time (as sent by the Channel Access server) is preferred.
However, when the difference between the time specified by the
archiving server’s system clock and the original time is greater than
the limit specified by the
maxClockSkew option,
the time from the local system clock is used instead.
The prefer_origin setting is used as the default
because it provides a reasonable balance between preferring a
time-stamp that is close to the point in time when the value was
actually measured and avoiding the use of completely bogus time-stamps
(or discarding samples) when a device server’s clock is not properly
synchronized.
The enablingChannel option specifies the name of a
channel that controls whether archiving is enabled.
This option is useful when a channel should only be archived when
certain conditions are met (e.g. the facility is in a certain state of
operation).
By default, the enablingChannel option is not set,
meaning that a channel is always archived (unless it has explicitly
been disabled in the configuration).
The channel name specified as the value of the
enablingChannel option can be any valid Channel
Access channel.
That channel does not have to be present in the Cassandra PV
Archiver’s configuration.
When the enabling channel is not connected, archiving is disabled.
When the enabling channel is connected, archiving is enabled depending
on the enabling channel’s value.
When the enabling channel’s value is of an integer type, the target
channel is enabled if the enabling channel’s value is non-zero.
When the enabling channel’s value is of a floating-point type, the
target channel is enabled when the enabling channel’s value is neither
zero nor not-a-number.
When the enabling channel’s value is of a string type, the target
channel is enabled when the enabling channel’s value is neither the
empty string, nor “0”, “false”, “no”, or “off”.
Leading and trailing white-space is ignored for this comparison and
the comparison is not case sensitive.
If this option is not set or set to the empty string (the default), archiving is always enabled. If a channel has been disabled in the archiving configuration, this option does not have any effect and archiving always stays disabled, regardless of the enabling channel’s connection state and value.
The maxClockSkew option specifies the maximum
difference that is allowed between the time sent by the Channel Access
server (together with the sample’s value) and the local system clock
of the archiving server.
The specified value must be a finite, non-negative floating point
number that specifies the maximum clock skew in seconds. The default
value is 30 seconds.
The effects of this option depend on the
clockSource option.
When the clockSource option is set to “local”, this
option does not have any effects.
When the clockSource option is set to
“prefer_origin”, this option controls which clock source is selected.
When this option is set to zero or the difference between the time
specified by the Channel Access server and the time specified by the
archiving server’s system clock is less than the limit specified by
this option, the time provided by the Channel Access server is used as
the sample’s time stamp.
When this option is non-zero and the difference between the time
specified by the Channel Access server and the time specified by the
archiving server’s system clock is greater than the limit specified by
this option, the time provided by the archiving server’s system clock
is used as the sample’s time stamp.
When the clockSource option is set to “origin”,
this option controls when a sample is discarded.
When this option is set to zero or the difference between the time
specified by the Channel Access server and the time specified by the
archiving server’s system clock is less than the limit specified by
this option, the sample is archived and the time provided by the
Channel Access server is used as the sample’s time stamp.
When this option is non-zero and the difference between the time
specified by the Channel Access server and the time specified by the
archiving server’s system clock is greater than the limit specified by
this option, the sample is discarded without being archived.
The maxUpdatePeriod option specifies the longest
period that may pass between writing two samples.
The specified value must be a finite, non-negative floating point
number that specifies the maximum period (specified in seconds)
between writing two samples.
The default value is zero, which means that a sample is only written
when the Channel Access server sends an update.
By using this option, one can ensure that a new sample repeating the
value of the previous sample is written when no new sample is received
from the Channel Access server within the specified period of time.
Typically, it makes sense to combine this option with the
writeSampleWhenDisabled
and
writeSampleWhenDisconnected
options.
Due to processing delays, the actual period between writing the two
samples might be slightly greater than the specified period.
For obvious reasons, the time stamp used when writing a sample without
having received an update from the Channel Access server is always
generated using the archiving server’s system clock, regardless of the
clockSource option.
Mixing samples that use the archiving server’s system clock for
generating the time-stamp with samples that use the time stamp
provided by the Channel Access server can have the effect that
updates that are received from the Channel Access server are actually
not archived because a previously written sample has a (slightly)
greater time stamp and the newer sample is therefore discarded (the
Cassandra PV Archiver server never writes samples that have a time
stamp less than or equal to a previously archive sample).
For this reason, it is recommended to set the
clockSource option to local
when setting this option to a non-zero value.
The metaDataMonitorMask option specifies the
monitor mask that is used for monitoring a channel for meta-data
(engineering units, alarm and display limits, etc.) changes.
The bit of the monitor mask is set when the corresponding token (one
of “value”, “archive”, “alarm”, and “property”) is present.
Tokens can be separated by commas, pipes, or spaces.
Please refer to the
Channel Access Reference Manual
for details about the meaning of this mask bits.
The event mask used when monitoring a channel for value changes is
specified separately through the
monitorMask option.
The default value for this option is “property”, which should
typically have the effect that an update is sent by the server when
one of the meta-data properties changes.
The minUpdatePeriod option specifies the shortest
period that must pass between writing two samples.
The specified value must be a finite, non-negative floating point
number that specifies the minimum period (in seconds) between writing
two samples.
The default value is zero, which means that a sample is always written
when the Channel Access server sends an update, regardless of the time
that has passed since receiving the last update.
By using this option, one can limit the rate at which samples are written. This is useful when a Channel Access server sends updates at a much higher rate than they should be archived. However, for very high update rates, samples might still be lost if the system cannot process them as quickly as they arrive.
The monitorMask option specifies the
monitor mask that is used for monitoring a channel for value and alarm
state changes.
The bit of the monitor mask is set when the corresponding token (one
of “value”, “archive”, “alarm”, and “property”) is present.
Tokens can be separated by commas, pipes, or spaces.
Please refer to the
Channel Access Reference Manual
for details about the meaning of this mask bits.
The event mask used when monitoring a channel for value changes is
specified separately through the
monitorMask option.
The default value for this option is “archive|alarm”.
When not using the
minUpdatePeriod option,
a sample is written for each update that is received from the Channel
Access server.
For this reason, the monitor mask has an effect on the rate at which
samples are written.
Most Channel Access servers send updates at a lower rate when setting
the “archive” instead of the “value” bit, which is why this bit is
used in the default value for this option.
The “alarm” bit, on the other hand, triggers an update each time the
channel’s alarm state changes.
The writeSampleWhenDisabled option allows for
writing a sample when a channel is disabled.
This option is enabled by setting it to “true”.
By default, it is set to “false”, which disables this option.
Typically, it makes sense to combine this option with the
maxUpdatePeriod
and
writeSampleWhenDisconnected
options.
When this option is enabled, a special sample acting as a marker for the disabled state is written to the archive when a channel is disabled. A channel can be disabled in the archive configuration or through an enabling channel. By writing such a marker sample, one can tell from the archived data whether a value simply did not change for an extended period of time or no samples where written because archiving was disabled.
When writing a marker sample to indicate that archiving is disabled,
the time from the archiving server’s system clock is used, regardless
of the
clockSource option.
Mixing samples that use the archiving server’s system clock for
generating the time-stamp with samples that use the time stamp
provided by the Channel Access server can have the effect that
updates that are received from the Channel Access server are actually
not archived because a previously written sample has a (slightly)
greater time stamp and the newer sample is therefore discarded (the
Cassandra PV Archiver server never writes samples that have a time
stamp less than or equal to a previously archive sample).
For this reason, it is recommended to set the
clockSource option to local
when enabling this option.
The writeSampleWhenDisconnected option allows for
writing a sample when a channel is disconnected.
This option is enabled by setting it to “true”.
By default, it is set to “false”, which disables this option.
When this option is enabled, a special sample acting as a marker for
the disconnected state is written to the archive when a channel is
disconnected.
By writing such a marker sample, one can tell from the archived data
whether a value simply did not change for an extended period of time
or no samples where written because the channel was not connected.
Typically, it makes sense to combine this option with the
maxUpdatePeriod
and
writeSampleWhenDisabled
options.
When writing a marker sample to indicate that the channel is
disconnected, the time from the archiving server’s system clock is
used, regardless of the
clockSource option.
Mixing samples that use the archiving server’s system clock for
generating the time-stamp with samples that use the time stamp
provided by the Channel Access server can have the effect that
updates that are received from the Channel Access server are actually
not archived because a previously written sample has a (slightly)
greater time stamp and the newer sample is therefore discarded (the
Cassandra PV Archiver server never writes samples that have a time
stamp less than or equal to a previously archive sample).
For this reason, it is recommended to set the
clockSource option to local
when enabling this option.
The Channel Access control-system support implements the generation of decimated samples in a way that should fit for most applications. This section explains how sample decimation is handled in different situations, in particular regarding the different possible types of raw samples.
For numeric, scalar samples, the Channel Access control-system support aggregates source samples in order to generate a decimated sample that represents the aggregated information of all its source samples. This process is described in Section 2.1, “Aggregation”. When the source samples cannot be reasonably aggregated (for example string samples or arrays), the Channel Access control-system support falls back to a simple decimation algorithm. This decimation algorithm is described in Section 2.2, “Decimation”.
Numeric, scalar source samples are aggregated when generating a
decimated sample.
Such source samples are of the types DBR_DOUBLE,
DBR_FLOAT, DBR_INT,
DBR_LONG, and DBR_SHORT and only
have a single element.
If the period that is covered by a decimated sample contains a sample
of type DBR_ENUM or DBR_STRING
or a sample that has more than one element, the algorithm falls back
to using the simple decimation algorithm that is described in
Section 2.2, “Decimation”.
When the source samples are of different types that are all
aggregatable, (e.g. DBR_DOUBLE and
DBR_SHORT), the samples of the type that covers the
greatest fraction of the period is used.
Samples of other types are not considered when building the aggregated
sample.
Source samples that indicate the channel being disabled or
disconnected are not used when building the aggregated sample either.
The generated aggregated sample contains the following information:
- mean of the source samples’ values
- standard deviation of the source samples’ values
- least source sample value (minimum)
- greatest source sample value (maximum)
- fraction of the total period that is covered by the source samples of that type
The mean and the standard deviation are calculated so that the validity period of each sample is used as its weight. For example, if the period for which a decimated sample is generated contains two samples and one of these two samples covers 90 percent of the period and the other one covers 10 percent of the period, the weight of the first sample is 0.9 and the weight of the second sample is 0.1. This way, the mean and the standard deviation give a more natural representation of the channel’s actual value during the whole period.
The fraction of the total period that is covered by the source samples of that type is kept for two reasons: First, it is needed when aggregating already aggregated samples further (for decimation levels with an even greater decimation period) in order to correctly calculate the weight of each sample. Second, it gives an idea of how much one can “trust” a sample. An aggregated sample that only covers a small fraction of the period is typically less reliable than an aggregated sample that covers a large fraction.
The meta-data of an aggregated sample (alarm limits, engineering units, etc.) is simply taken from the first source sample of the respective type. The alarm severity is taken from the source sample with the highest alarm severity. The alarm status is taken from that same sample. If there is more than one source sample with the highest alarm severity, the alarm status from the first of these samples is used.
When source samples cannot reasonably be aggregated (because they are of a non-numeric type or have values with more than a single element), a very simple decimation strategy is chosen. This strategy simply uses the first source sample, replacing its time stamp with the time of the start of the interval for which the decimated sample is generated. Decimated samples that are generated in this way are decimated in the literal sense and simply represent snapshots of the channel at specific points in time.
In the database, channels that use the Channel Access control-system
support can be identified by having their control-system type set to
“channel_access”.
The Channel Access control-system support stores all samples in a single
table with the name channel_access_samples.
The columns of this table are described by
Table D.1, “Columns of table channels_access_samples”.
| Column name | Column type | Data type | Description |
|---|---|---|---|
| channel_data_id | Partition key | uuid | Channel data ID. |
| decimation_level | Partition Key | int | Decimation level (identified by the decimation period in seconds). Zero indicates raw samples. |
| bucket_start_time | Partition Key | bigint | Start time of the sample bucket (in nanoseconds since epoch, which is January 1st, 1970, 00:00:00 UTC). |
| sample_time | Clustering Key | bigint | Time stamp of the sample (in nanoseconds since epoch, which is January 1st, 1970, 00:00:00 UTC). |
| a_char | Regular | frozen<channel_access_array_char> |
Data for a sample of type DBR_CHAR with more
than one element.
|
| a_double | Regular | frozen<channel_access_array_double> |
Data for a sample of type DBR_DOUBLE with
more than one element.
|
| a_enum | Regular | frozen<channel_access_array_enum> |
Data for a sample of type DBR_ENUM with more
than one element.
|
| a_float | Regular | frozen<channel_access_array_float> |
Data for a sample of type DBR_FLOAT with more
than one element.
|
| a_long | Regular | frozen<channel_access_array_long> |
Data for a sample of type DBR_LONG with more
than one element.
|
| a_short | Regular | frozen<channel_access_array_short> |
Data for a sample of type DBR_SHORT with more
than one element.
|
| a_string | Regular | frozen<channel_access_array_string> |
Data for a sample of type DBR_STRING with
more than one element.
|
| current_bucket_size | Static | int | Accumulated size (in bytes) of the samples that have been written to the sample bucket so far. |
| disabled | Regular | boolean | Marker for a sample indicating that the channel was disabled at that point in time. |
| disconnected | Regular | boolean | Marker for a sample indicating that the channel was disconnected at that point in time. |
| gs_char | Regular | frozen<channel_access_aggregated_scalar_char> |
Data for an aggregated sample that has been built from samples
of type DBR_CHAR, each having a single
element.
|
| gs_double | Regular | frozen<channel_access_aggregated_scalar_double> |
Data for an aggregated sample that has been built from samples
of type DBR_DOUBLE, each having a single
element.
|
| gs_float | Regular | frozen<channel_access_aggregated_scalar_float> |
Data for an aggregated sample that has been built from samples
of type DBR_FLOAT, each having a single
element.
|
| gs_long | Regular | frozen<channel_access_aggregated_scalar_long> |
Data for an aggregated sample that has been built from samples
of type DBR_LONG, each having a single
element.
|
| gs_short | Regular | frozen<channel_access_aggregated_scalar_short> |
Data for an aggregated sample that has been built from samples
of type DBR_SHORT, each having a single
element.
|
| s_char | Regular | frozen<channel_access_scalar_char> |
Data for a sample of type DBR_CHAR with a
single element.
|
| s_double | Regular | frozen<channel_access_scalar_double> |
Data for a sample of type DBR_DOUBLE with a
single element.
|
| s_enum | Regular | frozen<channel_access_scalar_enum> |
Data for a sample of type DBR_ENUM with a
single element.
|
| s_float | Regular | frozen<channel_access_scalar_float> |
Data for a sample of type DBR_FLOAT with a
single element.
|
| s_long | Regular | frozen<channel_access_scalar_long> |
Data for a sample of type DBR_LONG with a
single element.
|
| s_short | Regular | frozen<channel_access_scalar_short> |
Data for a sample of type DBR_SHORT with a
single element.
|
| s_string | Regular | frozen<channel_access_scalar_string> |
Data for a sample of type DBR_STRING with a
single element.
|
The channel_data_id,
decimation_level, and
bucket_start_time form a composite partition key that
identifies the sample bucket.
These parameters are passed to the control-system support by the
Cassandra PV Archiver server and are simply used “as-is”.
The sample_time is used as the clustering key.
This way, it is easily possible to select only those samples from a
sample bucket that have a time stamp within a specific interval.
The current_bucket_size is a static column because it
obviously is the same for the whole sample bucket.
This column is updated by the control-system support each time a sample
is added to the sample bucket.
All other columns are used for storing the sample’s data.
For each sample, exactly one of these columns has a non-null value.
The disabled and disconnected
columns are simple boolean columns.
If one of them is true, it means that the sample is
a marker of the corresponding type.
Each column that stores a regular (non-marker) sample uses a
user-defined type (UDT) that is only used by that column.
| Note |
|---|---|
The names of the data columns have intentionally been chosen to be very short. The reason for this is simple: Due to how regular columns are internally handled by Cassandra, the column name is serialized for each row. When there are many rows, a long column name can contribute to the total data size significantly. Most of this overhead is compensated by the compression that is applied to SSTables before storing them on disk. However, the sample bucket size that is limited to about 100 MB is measured before applying the compression. For this reason, longer column names would significantly reduce the number of samples that could be stored in each sample bucket. User-defined types (UDTs) are used for the same reason: When the various fields that are needed to store a sample would be represented as separate columns, the overhead that is caused by the meta-data for each column would increase the total data size significantly. Frozen UDTs, on the other hand, are as efficient as frozen tuples, allowing for the space-efficient storage of sample data while having human-readable names for their fields. |
The UDTs that are used by the Channel Access control-system support all share a similar structure. The fields that may be present in these UDTs are listed in Table D.2, “Fields of the user-defined types”.
| Field name | Data type | Description |
|---|---|---|
| value | depends on UDT | sample’s value. |
| std | double | standard deviation for an aggregated sample. |
| min | double | least original value for an aggregated sample. |
| max | double | greatest original value for an aggregated sample. |
| covered_period_fraction | double |
fraction of the period that is actually covered by the data in
the aggregated sample.
A value of 1.0 means that the data that was
used to calculate the aggregated sample actually covers the full
period that is supposed to be represented by the aggregated
sample.
A value of 0.5 means that the data that was
used to calculate the aggregated sample actually only covers
half of the period that is supposed to be covered by the
aggregated sample.
|
| alarm_severity | smallint |
alarm severity (0 means
NO_ALARM, 1 means
MINOR, 2 means
MAJOR, 3 means
INVALID).
|
| alarm_status | smallint | alarm status (the number is the status code that is used by the Channel Access protocol to signal the corresponding alarm status). |
| precision | smallint | display precision for floating point numbers. |
| units | text | engineering units. |
| labels | frozen<list<text>> | labels for enum states. |
| lower_warning_limit | depends on UDT | lower warning limit. |
| upper_warning_limit | depends on UDT | upper warning limit. |
| lower_alarm_limit | depends on UDT | lower alarm limit. |
| upper_alarm_limit | depends on UDT | upper alarm limit. |
| lower_display_limit | depends on UDT | lower display limit. |
| upper_display_limit | depends on UDT | upper display limit. |
| lower_control_limit | depends on UDT | lower control limit. |
| upper_control_limit | depends on UDT | upper control limit. |
Not all of these fields are present in each UDT.
The value, alarm_severity, and
alarm_status fields are the only ones that are
present in all UDTs.
The std, min,
max, and covered_period_fraction
fields are only present in the
channel_access_aggregated_* UDTs.
The precision field is only present in UDTs
representing samples of a floating-point type.
The units, lower_warning_limit,
upper_warning_limit,
lower_alarm_limit,
upper_alarm_limit,
lower_display_limit,
upper_display_limit,
lower_control_limit, and
upper_control_limit fields are only present in UDTs
that represent samples of a numeric type.
The labels field is only present in the
channel_access_array_enum and
channel_access_scalar_enum UDTs.
The type of the value field depends on the type of
the sample that is represented by the UDT.
The same applies to the lower_warning_limit,
upper_warning_limit,
lower_alarm_limit,
upper_alarm_limit,
lower_display_limit,
upper_display_limit,
lower_control_limit, and
upper_control_limit fields.
The types used for those fields are listed in
Table D.3, “Type of UDT fields”.
| User-defined type | Value field type | Limit fields type |
|---|---|---|
| channel_access_aggregated_scalar_char | double | tinyint |
| channel_access_aggregated_scalar_double | double | double |
| channel_access_aggregated_scalar_float | double | float |
| channel_access_aggregated_scalar_long | double | int |
| channel_access_aggregated_scalar_short | double | smallint |
| channel_access_array_char | blob | tinyint |
| channel_access_array_double | blob | double |
| channel_access_array_enum | blob | n/a |
| channel_access_array_float | blob | float |
| channel_access_array_long | blob | int |
| channel_access_array_short | blob | smallint |
| channel_access_array_string | blob | n/a |
| channel_access_scalar_char | tinyint | tinyint |
| channel_access_scalar_double | double | double |
| channel_access_scalar_enum | smallint | n/a |
| channel_access_scalar_float | float | float |
| channel_access_scalar_long | int | int |
| channel_access_scalar_short | smallint | smallint |
| channel_access_scalar_string | text | n/a |
For aggregated samples, the value field is always of
type double because it stores the mean of all source
samples.
The array types store the value elements in a blob.
The reason for this is that Cassandra’s list type
comes with an overhead that is significant when representing a large
number of elements as it is commonly encountered for Channel Access
channels that have array values.
Storing these arrays inside a blob is very efficient
because the size occupied by each element is not more than the element’s
actual size (e.g. two bytes for a each element of a
DBR_SHORT sample).
The numbers inside the blob are stored in big endian
format, so that when using Java, they can easily be converted back to
numbers by interpreting the ByteBuffer
representing the blob as a buffer of numbers (e.g. an
IntBuffer for samples of type
DBR_LONG).
For array samples of type DBR_STRING, the blob stores
40 bytes for each element.
These 40 bytes represent the raw value as it has been received from the
Channel Access server.
The complete list of Java element and buffer types that correspond to
the data stored in the value fields of the array UDTs
is given by
Table D.4, “Java types corresponding to blobs storing sample values”.
| User-defined type | Java element type | Java buffer type |
|---|---|---|
| channel_access_array_char | byte | ByteBuffer |
| channel_access_array_double | double | DoubleBuffer |
| channel_access_array_enum | short | ShortBuffer |
| channel_access_array_float | float | FloatBuffer |
| channel_access_array_long | int | IntBuffer |
| channel_access_array_short | short | ShortBuffer |
| channel_access_array_string | byte[40] | ByteBuffer |