The Cassandra PV Archiver is a scalable archiving solution for storing time-series data inside an Apache Cassandra database. While the Cassandra PV Archiver has been designed to archive the values of process variables in industrial automation scenarios, it is not limited to this specific application. In fact, it is suitable to archive any kind of data that can be represented as a time-series and new data sources can easily be added through extensions (see Chapter V, Extending Cassandra PV Archiver). The default distribution is bundled with a modules that allows for easy archiving of process variables that can be accessed over the Channel Access protocol, which is typically used in EPICS-based control systems.
This document is intended as a reference guide for administrators that want to deploy the Cassandra PV Archiver, developers that want to extend it, and user that want to manage the archiver’s configuration or to access archived data.
This chapter should be of interest to all audiences. In addition to that, administrators are most likely going to be interested in Chapter II, What’s new in Cassandra PV Archiver 3.x and Chapter III, Cassandra PV Archiver server. Developers are most likely going to be interested in Chapter V, Extending Cassandra PV Archiver. Users are most likely going to be interested in Chapter IV, Cassandra PV Archiver clients.
In addition to reading this document, administrators and developers who are not familiar with Apache Cassandra databases are encouraged to read the Cassandra documentation provided by DataStax.
The Cassandra PV Archiver acts as a bridge between an Apache Cassandra database and control-system applications. It takes care of monitoring process variables for changes and persisting them in the database. At the same time, it provides an interface for querying the data stored in the database in a convenient way, without having to deal with low-level details like the exact storage layout. The architecture of the Cassandra PV Archiver is depicted in Figure I.1, “Cassandra PV Archiver architecture”.
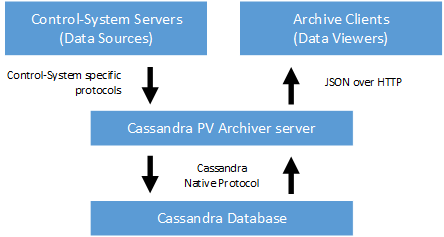
The control-system servers provide process variables that are monitored by the Cassandra PV Archiver server. The Cassandra PV Archiver can support arbitrary control-systems through so-called control-system supports. The Cassandra PV Archiver server is bundled with a control-system support for the Channel Access protocol (see Appendix D, Channel Access control-system support), but it can easily be extended with other control-system supports (see Chapter V, Extending Cassandra PV Archiver). The protocol used for communication between the control-system entirely depends on the control-system support, so that the control-system’s native protocol can be used for optimal performance.
The Cassandra PV Archiver server takes care of managing archived process variables (which are called “channels” in the terminology of the Cassandra PV Archiver). This includes managing configuration and meta-data as well as storing the archived samples in the Cassandra database. However, the actual storage format of individual samples is defined by each control-system support. This allows each control-system support to choose a storage format that is optimized for the structure of samples as they are supplied by the underlying control-system framework.
The Cassandra PV Archiver server uses Cassandra’s native protocol for writing data to and reading data from the Apache Cassandra database. Even though the Cassandra PV Archiver and the Cassandra database are depicted as monolithic blocks in Figure I.1, “Cassandra PV Archiver architecture”, each of these blocks can actually consist of many sever instances that form a cluster. The Cassandra PV Archiver server instances and the Apache Cassandra database servers can be deployed on separate clusters, but in a typical setup they will actually be colocated on the same servers.
For accessing archived samples, a user uses an archive client (see Chapter IV, Cassandra PV Archiver clients). This archive client accesses the Cassandra PV Archiver server through a JSON-based web-service protocol. Each server instance can provide access to the complete archive, so a client can use a round-robin strategy when choosing the server that is contacted in order to retrieve data. As an alternative to that, special server instances that are dedicated to providing read access to the archive might be deployed.