Clients for the Cassandra PV Archiver allow users to query the archive, retrieving archived samples for each channel. For most users, the plugin for Control System Studio’s Data Browser (see Section 1, “Control System Studio” ) is the easiest option for accessing the archive. However, other clients are supported as well through an open web-service interface. Please refer to Section 2, “Other clients” for details.
The Data Browser view of Control System Studio (CSS) provides powerful tools for finding, plotting, and exporting archived data. Integration with the Cassandra PV Archiver is provided by the JSON Archive Proxy client plugin. Please download the newest version of the JSON Archive Proxy that matches your version of CSS.
In order to install the plugin, the files from the
archive-json-reader-plugins
directory in the
distribution archive have to be copied to the
plugins
directory of the CSS installation.
The
source
files can, but do not have to be included.
For some versions of CSS, the plugin is detected automatically
the next
time CSS is started.
For other versions, it is necessary
to register the plugin manually
(e.g. by manually adding the two
bundles to
configuration/org.eclipse.equinox.simpleconfigurator/bundles.info
).
After starting CSS, the Cassandra PV Archiver has to be added as a data source. In the preferences, go to → → (see Figure IV.1, “CSS Data Browser options in the preferences tree” ).
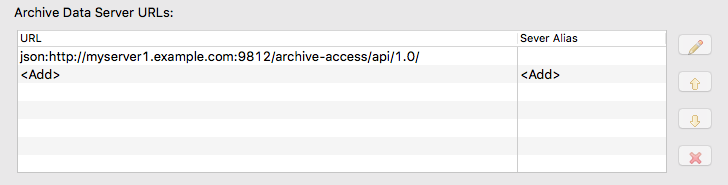
The archive URL has to be added to the list of
“Archive Data
Server URLs” (see
Figure IV.2, “CSS Data Browser archive data server URLs”
).
The URL is
http://server>:9812/archive-access/api/1.0/
, where
<server>
has to be replaced by the host name or
IP address of one of the
archive servers of course.
The port is 9812 unless the archive
access port has been changed in the
server’s configuration.
For a large installation, one should provide a load balancer that forwards requests, distributing them over the whole cluster. This also has the advantage that clients will still work when one of the servers is down. For the latter benefit, the load balancer itself has to be part of a high availability setup, of course.
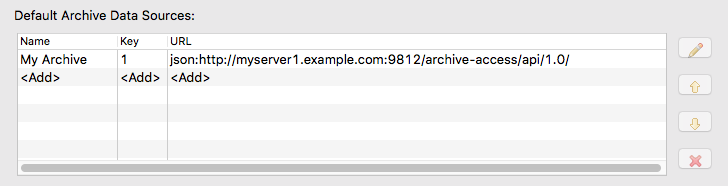
In addition to adding the URL to the list of “Archive Data Server URLs”, it can also be added to the list of “Default Archive Data Sources” (see Figure IV.3, “CSS Data Browser default archive data sources” ). Strictly speaking, this is not necessary for retrieving data from the archive, but it has the advantage that the archive can be used as a data source when no data source has been selected explicitly (e.g. when using historic data for a trend plot in a BOY panel). The key used for the Cassandra PV Archiver is always 1.
After adding the data source to CSS, CSS has to be restarted in order for the changes to take effect. After restarting, the archive can be accessed from the “Data Browser” perspective (see Figure IV.4, “CSS Data Browser perspective” ).
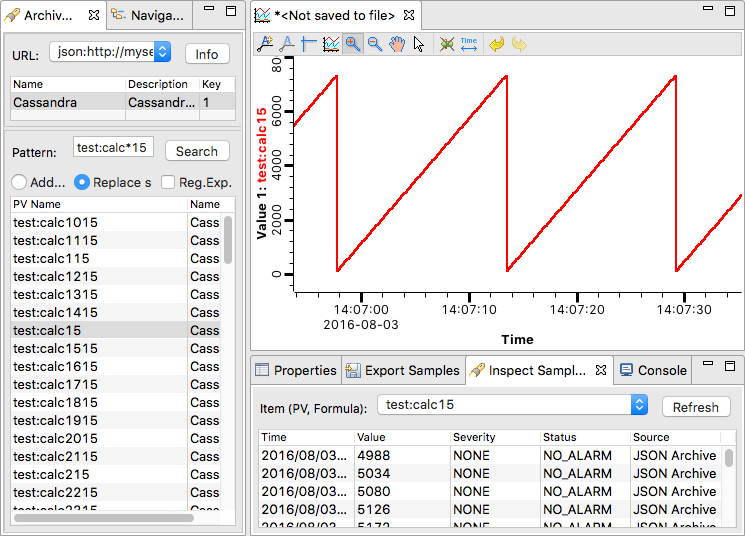
After seleting the archive URL from the list, one can search for
channels.
The search expression may contain glob patterns (e.g.
myC*5
,
myChannel?
, etc.).
Alternatively, regular expression may be used.
The data
for a channel can be plotted by right clicking it in the result
list and selecting
→
from the context menu.
When there is already an open trend plot,
one can add additional
channels to this plot by simply dragging
channels from the result list
and dropping them on the plot.
The data that is visible in the plot can also be examined through the “Inspect Samples” view. In addition to that, it can be exported into a file through the “Export Samples” view. When using the “Export Samples” view and selecting “Optimized Archived Data”, the most appropriate decimation level of the channel (the one which returns a number close to the requested number) is used. When selecting “Raw Archived Data”, only raw samples are used.